Link to the 'new' book, courses, software and much more
. + . + . + .
The semi-variogram
Complex models
Log-normality
Other variables
Conclusion
Chapter 3 THE VOLUME--VARIANCE RELATIONSHIP
Regularisation
Volume-variance calculations
Grade/tonnage curves
Conclusion
Estimation
Calculation of gamma-bar terms
Two-dimensional examples
Summary of major points
Some more complex problems
Kriging
Kriging examples
Summary of major points
Simulated iron ore example
Link to the 'new' book, courses, software and much more
. + . + . + .
This book is aimed at postgraduates, undergraduates and workers in industry who require an introduction to geostatistics. It is based on seven years of courses to undergraduates, M.Sc. students and short courses to industry, and reflects the problems which have been encountered in presenting this material to mining engineers and geologists over a wide age range, and with an equally wide range of numerical ability. The book would provide the foundation of a course of about 20 to 30 hours, or of a five-day short course.
The level of mathematical and statistical ability required is fairly rudimentary; it is sufficient to be able to cope with concepts like mean, variance, standard error of the mean, normal and log-normal distributions, and to have some notion of the background to solving sets of simultaneous equations.
As an introduction to a subject which is commonly presented as rather complex, the book will familiarise the reader with the concepts and techniques of geostatistics, providing the necessary foundation to enable him or her to evaluate basic idealised examples. It also gives an indication of how to employ the techniques in more complex and realistic situations.
Geostatistics is used throughout this book in its European sense of the 'Theory of Regionalised Variables', developed by Georges Matheron and co-workers at the Centre du Morphologie Math�matique at Fontainebleau. Although most of the examples are drawn from mining, this reflects the distribution of practitioners rather than the potential of the techniques. Practically any problem which involves the distribution of some variable in one dimension (e.g. time series), two dimensions (e.g. rainfall), or three dimensions (e.g. disseminated ore deposits) can be solved using such a technique.
The units of measurement used in the book also reflect the state of the mining industry. No attempt has been made to standardise to SI units. The examples are real examples, and it seems absurd to turn, for example, 5-ft cores into 1.52-m cores. The one case where this seems to have been done is an actual example where the mine involved had adopted SI units, but continued to use its pre-metric 5-ft core boxes.
In the presentation of the material I have tried to show how the basic ideas may be developed intuitively, and I have tended to avoid supporting the ideas with a rigorous mathematical derivation, since there are numerous existing publications which use this latter approach almost exclusively. While many computational difficulties can be eased by use of computer programs, such assistance should not be needed within the scope of this text. None of the examples is too unwieldy for pencil and paper, far less for a calculator. Where formulae are too complex (or tedious) to calculate by hand, tables have been provided. One example has been included (the simulated iron ore body) so that some experience may be gained at tackling a fairly realistic example, to see whether the reader can reproduce the author's result.
Acknowledgements are due to Richard Durham, who provided some of the examples and the simulated iron ore body; Reg Puddy who produced the splendid drawings; Dr. C. G. Down who created the situation which obliged me to write the book; Malcolm Clark who baby-sat and produced some of the prettier tables; and finally to Andr� Journel and others at Fontainebleau who taught me all I know about the theory of the Theory of Regionalised Variables. Any shortcomings and inaccuracies in the text lie with me.
ISOBEL CLARK
January 1979
. + . + . + .
| h, d, b, l | distances or lengths |
| γ(h) | semi-variogram between two points -- theoretical model |
| γl(h) | semi-variogram between two cores along the same borehole |
| γ*(h) | experimental point semi-variogram |
| γl*(h) | experimental core semi-variogram |
| γ(l;b) | semi-variogram between two parallel cores |
| χ(l) | semi-variogram between a point and a line |
| χ(l;b) | semi-variogram between a line and a panel |
| H(l,b) | semi-variogram between a point and a panel |
| F(l) | variance of grades within a line |
| F(l,b) | variance of grades within a panel |
| F(l,b,d) | variance of grades within a block |
| average value of the semi-variogram between two specified 'areas' | |
| a | range of influence of a semi-variogram |
| C | sill of a semi-variogram |
| C0 | nugget effect |
| p | slope of the linear semi-variogram |
| α | parameter in generalised linear and de Wijsian semi-variogram |
| g | grade (value) |
| s | standard deviation of the grades |
| arithmetic mean of the grades (simple average) | |
| y | logarithm of the grade |
| mean value of the logarithm of the grade | |
| sy | standard deviation of the logarithm of the grade |
| z | Standard Normal deviate |
| φ(z) | height of the Standard Normal probability density function |
| Φ(z) | probability that a Standard Normal variate is less than z |
| c | cutoff value, selection criterion |
| average grade above cutoff | |
| P | proportion of th eore which is above cutoff |
| A | 'area' to be estimated |
| T | unknown grade of the area to be estimated |
| S | sample set available for estimation |
| T* | estimator formed from the sample values |
| wi | weight accorded to sample i |
| σε | standard error of a linear estimate |
| σe | standard error of the arithmetic mean of the samples |
| σk | standard error of kriging estimate |
| δθ, δh | a small angle, a small distance |
. + . + . + .
Perhaps it would be useful here at the very beginning to clear up any possible ambiguity which arises because of the use of the title Geostatistics. In the early 1960s, after much empirical work by authors in South Africa, Georges Matheron, now Head of the Centre de Morphologie Math�matique in Fontainebleau, France, published his treatise on the Theory of Regionalised Variables. The application of this theory to problems in geology and mining has led to the more popular name Geostatistics. The contents of this book are confined to the simplest application of the Theory of Regionalised Variables, that of producing the 'best' estimation of the unknown value at some location within an ore deposit. This technique is known as kriging. The purpose of this text is to provide a simple treatment of Geostatistics for the reader unfamiliar with the field. The subject may be discussed at a number of levels of mathematical complexity, and it is the intention here to keep the mathematics to a necessary minimum. Some previous knowledge must be assumed on the reader's part of basic concepts of ordinary statistics such as mean, variance and standard deviation, confidence intervals and probability distributions. Readers without this background are referred to any one of a large number of excellent basic texts.
The application of Geostatistics to the estimation of ore reserves in mining is probably its most well known use. However, it has been emphasised time and again that the estimation techniques can be used wherever a continuous measure is made on a sample at a particular location is space (or time), i.e., where a sample value is expected to be affected by its position and its relationships with its neighbours. Since most applications -- and most of the author's experience -- are confined to the mining field, so will most of the examples in this book. Also, there will be a tendency to talk of 'grades' rather than 'sample values', for brevity if nothing else. If the reader is interested in other fields, it suffices to replace 'grade' by porosity, permeability, thickness, elevation, population density, rainfall, temperature, fracture length, abundance or whatever.
The application of statistical methods to ore reserve problems was first attempted some 30 years ago in South Africa. The problem was that of predicting the grades within an area to be mined from a limited number of peripheral samples in development drives in the gold mines. Gold values are notoriously erratic, and when plotted in the form of a histogram show a highly skewed distribution with a very long tail into the rich grades. Normal (Gaussian) statistical theory will not handle such distributions unless a transformation is applied first. H. S. Sichel applied a log-normal distribution to the gold grades and achieved encouraging results. He then published formulae and tables to enable accurate calculation of local averages for log-normal variables, and also confidence limits on those local averages. Three major drawbacks exist in the application of Sichel's 't' estimator. The 'background' probability distribution must be log-normal. The samples must be independent. There is no consideration taken of the position of the samples -- all are equally important. However, the technique proved very useful in the gold mines, especially since some measure of the reliability of the estimator was provided. It also laid the base for further statistical work by providing the conceptual framework necessary, i.e., by assuming that the sample values came from some probability distribution. At this stage, it was assumed that all the samples (in a given area) came from the same probability distribution -- a log-normal one -- and this assumption is known in ordinary statistics as 'stationarity'.
Subsequent to this work attempts were made to incorporate position and spatial relationships into the estimation procedure. Two things seemed sensible: there should be 'rich' areas and 'poor' areas within a deposit; and there should be some sort of relationship between one area and the next. These were tackled in the 1950s and early 1960s by the introduction of Trend Surface Analysis. In South Africa, trends were picked out by forming a 'rolling mean' which produced a smoothed map so that high and low areas could be distinguished. In the United States a 'Polynomial Trend Surface' analysis was propounded which used a statistical technique to fit a mathematical equation to describe the trend. Both methods have one thing in common -- the basic assumptions about the statistical characteristics of the deposit. These assumptions have been extended from the 'stationarity' one, by stating that the sample value is expected to vary from area to area in the deposit. Some areas are expected to be rich, some to be poor. This expectation can be expressed as a reasonably smooth variation, either by a smoothed map or a relatively simple equation. Round about this trend there is expected to be random variation. That is, the value at any point in the deposit is supposed to comprise (i) a 'fixed' component of the trend (which is probably unknown), and (ii) a random variable following one specific distribution. Thus the stationarity has been shifted one step; the expected grade may vary slowly, but the random component is 'stationary'. We have also dropped the log-normality assumption. This approach is quite useful for an overview of the deposit, but, except in heavily sampled areas like the gold mines, is not really useful for local estimation.

Fig 1.1: Hypothetical sampling and estimation situation
Let us consider the problem of local estimation, e.g. of trying to estimate the value at, say, point A in Fig 1.1, given the samples at the various locations shown. It seems reasonable to evolve an estimation procedure which gives more importance to sample 1 than to sample 5. A whole range of methods have been produced to decide on the 'weight' accorded to each sample, mostly based on the distance of the sample from the point being estimated. Sample values may be weighted by inverse-distance, inverse-distance squared, or by some arbitrary constant (e.g. range of influence) minus the distance. All of these involve the same basic assumption -- that the relationship between the value at point A and any sample value depends on the distance (and possibly direction) between the two positions, and on nothing else. It does not depend on whether one is in a rich or poor zone, or on the actual sample values, but only on the geometric placing of the samples. In fact, it does not even depend on the mineral in the deposit!
There are some problems with this approach. Which weighting factors are the best to choose? How far do you go in including samples -- if there is a sample 6 which is twice as far away as sample 5, should it be included? How reliable is the estimate when we get it? Can we seriously expect the same estimation method to be equally valid on all types of deposits? On the other hand, the idea of weighting samples by some measure of their similarity to what is being estimated is intuitively appealing. It also seems to avoid those crippling restrictions on what distribution of values you can handle, which so limit the other methods of estimation. 'Similarity' can be measured statistically by the covariance between samples or by their correlation. However, to calculate either of these we have to go back to 'stationarity' type assumptions. Let us look instead at the difference between the samples.
In Fig 1.1 is seems sound to expect that the value at position 5 will be 'very different' from that at A, whilst sample 1, say, will have a value 'not very different' from that at A. Let us make an assumption that the difference in value between two positions in the deposit depends only on the distance between them and their relative orientation. Suppose we took a pair of samples 50ft apart on a north-south line in one part of the deposit, and measured the difference between the two values. Now, suppose we did the same, say, 200ft away. And again in yet another position, and so on. The value obtained (difference in grade) would be different for each pair of samples, but under our assumptions all of these values would be from the same probability distribution. Thus, if we could take enough such pairs, we could build up a histogram of the differences and investigate the distribution from which they were drawn. We would expect that distribution to be governed by the distance between the pair and the relative orientation, i.e. 50ft, north-south. Effectively, we have worked the implicit assumptions of the distance weighting techniques into a statistical form.
However, we will have one histogram for every different distance and direction in the deposit. To build up any useful picture of the deposit we need as many different distances and directions as possible. To investigate a histogram for each would be tedious and would overwhelm us with not terribly useful information. Let us resort to the usual trick of summarising the histogram in a couple of simple parameters. The usual ones are the arithmetic mean (average) and the variance, or equivalently the standard deviation. Suppose, for shorthand, we describe the distance between the samples and the relative orientation as h. We have said that the difference in grade between the two samples depends only on h. In statistical terms, the distribution of the differences depends only on h. If this is true of the whole distribution, it is also true of its mean and variance. That is, we can describe the mean difference in grade as m(h) and the variance of these differences as 2γ(h). If we had a set of pairs of samples for a specific h (say 50ft, north-south) then we could calculate an 'experimental' value for m(h).
![]()
where g stands for grade, x denotes the position of one sample in the pair and x+hthe position of the other, and n is the number of pairs which we have. You will have noticed the introduction of the '*' to show that this is something we have calculated rather than something 'theoretical'. Unfortunately, it can be shown that this is not a very good way of estimating m(h), and that to get a good way involves intense mathematical complications. Let us look closer at m(h) itself. It represents an average difference in grades between two samples -- in other words, an 'expected' difference. If m(h) is zero, this implies that we 'expect' no difference between grades a distance h apart. Put another way, we 'expect' the same sort of grades over an area of the deposit which is at least as large as h. In jargon terms, locally (within h) there is no trend. It is a convenient assumption to make for our purposes, so we will assume that there is no trend within the scale in which we are interested. We will see later what happens if this is not true.
Having rid ourselves of m(h), let us turn to the variance of the differences. This has been called 2γ(h) and is usually known as the variogram, since it varies with the distance (and direction) h. In practice, having made our no-trend assumption, we can calculate:
![]()
The '2' in front of the γ* is there for mathematical convenience. The term γ(h) is called the semi-variogram (although some authors sloppily call it the variogram), and γ*(h) is the experimental semi-variogram; γ* bears the same relationship to γ that a histogram does to a probability distribution.
Having defined a semi-variogram, what sort of behaviour do we expect it to have. We have a measure of the difference between the grades a distance (and direction) h apart. The measure which we have is in units of grade squared, e.g. (% by weight)�, (p.p.m.)� and so on, and we calculate a value for the experimental semi-variogram for as many different values of h as possible. The easiest way to display these figures is in a graph -- hence the name semi-variogram. It is usual to plot the graph as in Fig 1.2. That is, the distance between the pairs of samples is plotted along the horizontal axis and the value of the semi-variogram along the vertical. By definition h starts at zero, since it is impossible to take two samples closer than no distance apart. The γ axis also starts at zero, since it is an average of squared values.

Fig 1.2: Usual method of plotting a semi-variogram on a graph
Consider the case when h is equal to zero. We take two samples at exactly the same position and measure their values. The difference between the two must be zero, so that γ and γ* must always pass through the origin of the graph. Now suppose we let the two samples move a little distance apart. We would now expect some difference between the two values, so that the semi-variogram will have some small positive value. As the samples move further apart the differences should rise. In the ideal case when the distance becomes very large the sample values will become independent of one another. The semi-variogram value will then become more or less constant, since it will be calculating the difference between sets of independent samples. This so-called 'ideal shape' for the semi-variogram is shown in Fig 1.3, and is to Geostatistics as the Normal distribution is to statistics.

Fig 1.3: The 'ideal' shape for a semi-variogram -- the spherical model.
It is a 'model' semi-variogram and is usually called the spherical or Matheron model. The distance at which samples become independent of one another is denoted by a and is called the range of influence of a sample. The value of γ at which the graph levels off is denoted by C and is called the sill of the semi-variogram. The spherical model is given mathematically as:

This model was originally derived on theoretical grounds (as was the Normal distribution) but has been found to be widely applicable in practice.
There are many other possible models of semi-variograms, but only a few are commonly used. One other model with a sill which seems to have found some application is the exponential model. This is described by:
![]()
This model rises more slowly from the origin than the spherical and never quite reaches its sill. F igure 1.4 shows the spherical and exponential with the same range and sill. Figure. 1.5 shows the two with the same sill and the same initial slope for comparison. The reason for this will become clear in the next chapter.
Fig 1.4: Comparison of the exponential and spherical models with the same range and sill

Fig. 1.5: Comparison
of the exponential and spherical models with the same initial slope and sill.
One of the interesting properties of models with a sill -- both mathematically and for the applications -- is that the sill value, C, is equal to the ordinary sample variance of the grades. If you could take a set of random independent observations from the deposit and calculate the sample variance:
![]()
then s� and C will both be estimates of the same 'true' sample variance. The relationship between s� and C will be seen later to have wide-ranging consequences.
There are also models which have no sill. The simplest of these is the linear model:
![]()
where p is the slope of the line. An extension of this model is the 'generalised linear':
![]()
where α lies between 0 and 2 (but must not equal 2). This model is shown in Fig 1.6 for various values of α.

Fig 1.6. The linear and the generalised linear model
Another model without a sill is the de Wijsian model:
![]()
in which the semi-variogram is linear if plotted against the logarithm of the distance.
One other model exists, to describe the semi-variogram of a purely random phenomenon. Effectively, it is a spherical model with a very small range of influence. The 'nugget effect' as it is called, is given by:

Note that even with completely random phenomena the semi-variogram must be zero at distance zero. Two samples measured at exactly the same position must have the same value.
In practice, many semi-variograms comprise a mixture of two or more of these models and we shall see some of these in Chapter 2. To summarise our introduction to Geostatistics, here are the basic assumptions necessary for their application:
1. Differences between the values of samples are determined only by the relative spatial orientation of those samples.
2. We are really interested only in the mean and variance of the differences, so our real contention is that these two parameters depend only on the relative orientation. This is known as the 'Intrinsic Hypothesis'.
3. For convenience we have assumed that there is no trend on the deposit which is likely to affect values within the scale of interest. Thus we are only interested in the variance of the difference in value between the samples.
From these assumptions we have produced the notion of a semi-variogram, and we have discussed the sort of shape which we expect a semi-variogram to take. In the next chapter we will look at the process of actually calculating an experimental semi-variogram and trying to relate it to the models discussed.
. + . + . + .
We have seen in Chapter 1 how the definition of a semi=variogram arises out of the notions of 'continuity' and 'relationship due to position within the deposit'. The semi-variogram, γ, is a graph (and/or formula) describing the expected difference in value between pairs of samples with a given relative orientation. We also discussed the ideal forms which semi-variograms might take. We are now going to discuss calculated or 'experimental' semi-variograms.
Consider the data shown in Fig 2.1.

Fig
2.1. Example of data on a grid for the calculation of an experimental semi-variogram − iron ore.
We have here a stratiform iron orebody, through which a set of drill-holes have been bored, perpendicular to the dip of the ore. The value given at each location is the average value of Fe (% by weight) over the intersection of the borehole with the ore (see Fig 2.2). Essentially this is a two-dimensional problem, so that the h in our definition of the semi-variogram depends on the distance between the pair of samples, and their relative orientation in a two-dimensional plane.

Fig
2.2. Cross-section through the iron ore deposit.
Let us consider the east-west direction, and try to construct an experimental semi-variogram for this relative orientation. The grid on which the holes have been so conveniently placed is 100ft by 100ft, so that we can only calculate values of the experimental semi-variogram, γ*, for distances which are multiples of this. At zero we know that γ*(0) is equal to zero. At 100ft we need to find all pairs of samples at a separation of 100ft in the east-west direction. These are shown in Fig 2.3.

Fig 2.3. Identifying all the pairs at 100ft apart in the
east-west direction.
The calculation as defined says: take each pair; measure the difference in value between the two samples; square it; add up all the squares; divide this sum by twice the number of pairs. In our example:
| γ*(100) = [ | (40−42)2 + (42−40)2 + (40−39)2 + (39−37)2 + (37−36)2 |
| + (43−42)2 + (42−39)2 + (39−39)2 + (39−41)2 + (41−40) � + (40−38)2 + | |
| + (37−37)2 + (37−37)2 + (37−35) � + (35−38)2 + (38−37)2 + (37−37)2 + (37−33) � + (33−34)2 | |
| + (35−38)2 + (35−37)2 + (37−38) � + (38−36)2 + (36−35)2 | |
| + (36−35)2 + (35−36)2 + (36−35)2 + (35−34)2 + (34−33)2 + (33−32)2 + (32−29)2 + (29−28)2 | |
| + (38−37)2 + (37−35)2 + (29−30)2 + (30−32)2 ] ÷ (2 × 36) | |
| γ*(100) = | 1.46(%)2 |
This gives us one point which we can plot on a graph of the experimental semi-variogram γ* versus the distance between the samples (h), that is [100ft,1.46(%)2]. Now let us consider a distance between samples of 200ft.
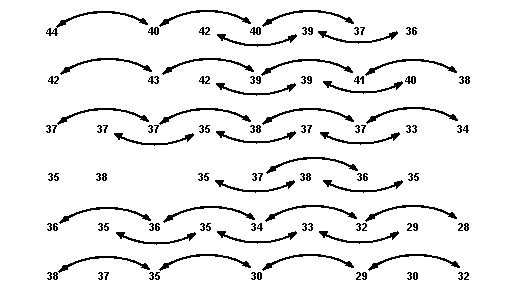
Fig 2.4. Identifying all the pairs 200ft apart in the east-west direction.
Figure 2.4 shows the pairs which lie at this distance in the east-west direction, and the calculation becomes:
| γ*(200) = [ | (44−40)2 + (40−40)2 + (42−39)2 + (40−37)2 + (39−36)2 |
| + (42−43)2 + (43−39)2 + (42−39)2 + (39−41)2 + (39−40) � + (41−38)2 | |
| + (37−37)2 + (37−35)2 + (37−38) � + (35−37)2 + (38−37)2 + (37−33)2 + (37−34) � | |
| + (38−35)2 + (37−36)2 + (35−38)2 | |
| + (36−36)2 + (35−35)2 + (36−34)2 + (35−33) � + (34−32)2 + (33−29)2 + (32−28)2 | |
| + (38−35)2 + (35−30)2 + (30−29)2 + (29−32)2 ] ÷ (2 × 33) | |
| γ*(200) = | 3.30(%)2 |
which we can plot on the graph versus 200ft.
The question now arises of where to stop. We could obviously continue up to distances of 800ft, for which we would have 7 pairs. In practice, we rarely go past about half the total sampled extent − in this case, say, 400ft. Table 2.1 shows the calculated points for the experimental semi-variograms in the east-west and in the north-south direction, and Fig 2.5 shows a plot of the two γ*s.
 Fig 2.5. Experimental semi-variograms in the two major directions for the iron ore example. |
Table 2.1.
Calculation of experimental semi-variogram values in two major directions for
iron ore example on square grid
|
There seems to be a distinct difference in the structure in the two directions. The north-south semi-variogram rises much more sharply than the east-west, suggesting a greater continuity in the east-west direction. To verify this, we should then calculate the semi-variogram in at least one 'diagonal' direction, e.g. northwest-southeast. These figures are shown in Table 2.2, and Fig 2.6 shows the three experimental semi-variograms plotted on the same graph.
 Fig 2.6. Experimental semi-variograms including a diagonal for the iron ore example. |
Table 2.2. Calculation of semi-variogram in diagonal direction for iron ore
|
Of course, the intervals at which the diagonal semi-variogram values are calculated are now multiples of 100√2=141 ft. The new γ* seems to verify the difference between the other two, since it lies between them − although it seems to be closer to the north-south than to the east-west. The conclusion which must be drawn is that more information is needed to determine the 'true' axis of the anisotropy. It would be rather optimistic to suppose that our drill grid was laid down in the exactly correct direction for the different structures. Secondly, we must decide whether, say, the last point on the diagonal semi-variogram is reliable. This was calculated on only 13 pairs, as opposed to the next lowest of 21. Does this mean we should place only two-thirds as much confidence on it? Some theoretical work on simple cases has been done at Fontainebleau, but in practice the only rule is: the fewer pairs, the less reliable.
The east-west semi-variogram seems to be reasonably consistent, and suggests a straight line with slope 6.5(%)2/400ft=0.01625(%)2/ft. Thus for the east-west direction:
![]()
For the north-south direction, the following seems reasonable:
![]()
That is, in the east-west direction, we 'expect' a squared difference of 0.01625(%)2 for each foot between the samples. Put another way, a difference in grade of √0.01625=0.1275%Fe is expected for two samples 1ft apart, with a relative orientation of east-west. In the north-south direction the corresponding figure is 0.2236%Fe. For samples 100ft apart, we would expect differences of 1.275%Fe (east-west) and 2.236%Fe (north-south) and so on. Thus we have built up a picture of the grade fluctuations within this section of the deposit, and have a fairly simple model to describe the differences in grade.
Table 2.3.
Hypothetical borehole log from lead/zinc deposit − Zinc values
|
|
|
|
Now let us turn to another example. Table 2.3 shows a borehole 'log' for one drill hole through a lead/zinc mineralisation which is disseminated in limestone. The first 45.40m go through barren rock, and the rest of the core has been divided into regular sections 1.52m (5ft) long. At one point, the core has been lost − perhaps due to a solution cavity in the limestone. As is the case in most three-dimensional deposits, there is very detailed information 'down' the borehole, but the boreholes are widely scattered over the deposit. The usual practice is to make 'down-the-hole' semi-variograms, and then to look at the horizontal directions as we did in the first example. So, for practice, let us calculate the experimental semi-variogram down this one borehole. Effectively the problem is simpler than the first one since we have one long line of regularly spaced samples with a single gap of 6.08m. Table 2.4 shows the calculated γ*, and Fig 2.7 the plot of this experimental semi-variogram versus the distance between the pairs.

Fig 2.7. Experimental semi-variogram calculated on one 'borehole'
through a hypothetical lead/zinc ore-body.
Table 2.4. Calculated
experimental semi-variogram from Lead/Zinc deposit
|
|
In this case the number of pairs of points decreases steadily as the distance increases, from 58 pairs at h=1.52m to 28 pairs at h=48.64m. Thus the most 'reliable' points on the graph are those for small distances, and the reliability drops off slowly and regularly. The semi-variogram seems to follow approximately the ideal shape discussed in Chapter 1. It rises from the origin, seems to more or less level off at about 15m, and continues with some variation around the value, say, of 10.5(%)2. We could probably fit a spherical model to this semi-variogram without further ado. However, let us look at the supposed variation around the sill. There is a dip in the curve at 25m, and another at about 35m. There is less difference between samples 25m apart than there is at 15m. If we go back to the drill log we find that the grade values seem to rise and fall quite regularly. There is a 'rich' patch centred at about 47m below collar, another at 81m and a possible third at 106m, where the core has been lost. The distances between these rich patches are 34m and 25m respectively. Thus the experimental semi-variogram is drawing our attention to the presence of localised rich areas down the borehole. The implications of this would need to be viewed in the light of other boreholes and/or information about the deposit. If the same sort of pattern occurs on many of the other boreholes then we would suspect some sort of lenticular (or stratified) structure. If the other boreholes do not reflect this regular rise and fall, this is probably just local fluctuation. This particular set of data was taken from a deposit with a marked (geologically) lenticular structure which had already been mapped on-site. This is one manifestation of what happens to the semi-variogram if 'trends' − in this case periodic trends − are present within the deposit and are ignored. On the other hand, for small scale estimation, say up to 20m in the vertical direction, a spherical model would be quite adequate.
Both of these illustrative examples have been carried out on small sets of data, so that the reader can check his understanding of the calculation by trying to reproduce the answers. The interpretation of an experimental semi-variogram is another matter, and is something that becomes easier with practice. I should like, therefore, to give a few examples of semi-variograms from my own experience.
Table 2.5 shows an experimental semi-variogram which was calculated on silver values from samples taken in a tabular, heavily-disseminated base-metal sulphide deposit. An access adit has been driven into the deposit and a vertical channel sample taken every metre along one wall of the tunnel.
Since the width of the ore is variable, the accumulation (grade times width) was calculated for each sample. 400m of the adit was sampled in this way, giving an unbroken succession of values. The units of accumulation are metres-per-cent(m%), so that the units of the experimental semi-variogram are (m%)2. Figure 2.8 shows the graph of this semi-variogram versus distance. Near the origin, the points form an almost straight line. This is a characteristic of most of the common semi-variogram models.

Fig
2.8. Experimental semi-variogram constructed on the silver values from a complex sulphide deposit.
The curve rises, flattens off at about 11(m%)2, and then rises again more and more rapidly. In fact, after a distance of about 75m, the curve is virtually parabolic. This is an indication of the presence of a polynomial-type trend within the deposit. There appears to be a smoothly varying large scale trend in operation here. If we wished to consider points more than, say, 75m apart in any estimation procedure, then we should have to take account of that trend (see Chapter 6). However, if we restrict consideration to areas within the deposit of no more than 75m in radius, the problem may be safely ignored. Let us, then, look at the semi-variogram only up to distances of 75m (see Fig 2.9). A 'sill' appears to exist at C=11(m%)2. A horizontal line has been drawn onto the graph at this level.
A more difficult parameter to 'eyeball' is the range of influence a. It can be shown that if a spherical model is to be used − as seems to be indicated by the flat nature of the sill − then a line drawn through the first few points of the experimental semi-variogram will intersect the sill at a distance equal to two-thirds of a. Doing this on Fig 2.9 produces a value of 33m for the intersection, giving a range of influence of approximately 50m.

Fig
2.9. First estimation of model and parameters for the silver semi-variogram.
Indications are that we need a spherical model with a range of influence of 50m and a sill of 11(m%)2. Since there is no objective (statistical) way of deciding whether a model fits an experimental semi-variogram, the only simple method is to draw the model curve onto the same graph as the experimental one. The equation for this model is:

This curve has been drawn onto the same graph as the experimental points, and the result is shown in Fig 2.10. The numerical values for various points on the model curve are given in Table 2.6.
 Fig 2.10. Fitted spherical model to silver semi-variogram. |
Table 2.6. Spherical semi-variogram model for silver values up to h = 75m
|
This seems to give a fairly good fit. It is difficult to see how it might be improved. Sometimes the two parameters require adjustment before an adequate fit is found. Note that the model has only been fitted for distances up to 75m. Beyond this the trend must be taken into account. In this case we were very lucky, in that the trend does not 'interfere' until after the range of influence is passed. This is not always so, and the closer the parabolic behaviour is to the origin the more heed must be paid to the trend.
It might be argued that a more suitable model for this semi-variogram would be the exponential model.
For interest, let us take the sill again at 11(m%)2. For an exponential model the straight line through the origin intersects the sill at a distance equal to the range of influence. That is, if we try an exponential model the range will be 33m.
![]()
Figure 2.11 shows the model, alongside the data points.
 Fig 2.11. Exponential model with same parameters as fitted spherical (for silver semi-variogram). |
Table 2.7 Attempts to fit exponential models to silver semi-variogram
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The slope at the origin is correct but the rest of the curve is far too low. We can increase the sill to bring up the values, but we also need to increase the value of the range of influence, so that the behaviour near the origin is still correct. Table 2.7 shows the 'model' values given by various sets of parameters − sill and range of influence.
Round figures have been used for simplicity, but the 'best' exponential fit seems to be the last one, with a=50m and C=16(m%)2. Figure 2.12 compares the fit of this curve with the previous spherical model, and with the experimental semi-variogram. I prefer the spherical model because it seems to fit the data between 15 and 40m better than the exponential. Only a minority of the observed points fall below the exponential curve. A shortening of the range of influence to compensate for this results in a marked change in slope at the beginning of the curve.

Fig
2.12. Comparison of final models − exponential and spherical − for silver semi-variogram.
* * * * * *
Now let us try some real semi-variograms, rather than these hand-picked simple ones. Figure 2.13 shows the experimental semi-variograms for three metals in another complex base-metal sulphide. The metal of economic importance is the copper, but the other two metals are of sufficient value to warrant investigation. The semi-variograms are 'down-the-hole' in direction, and contain information from about 50 boreholes perpendicular to the plane of the ore-body.

Fig
2.13. Experimental semi-variograms for a complex base-metal sulphide deposit.
My interpretation of the lead and zinc semi-variograms is pure nugget effect. That is, the 'model' is a horizontal line at a value equal to the sample variance. There appears to be very little relationship even between neighbouring cores! On the other hand, the copper semi-variogram appears to be a combination of a nugget effect (constant) and a parabola. As in the previous example, the parabola implies a polynomial trend, in this case acting on pairs of samples even at 1m spacing. The nugget effect implies completely random behaviour. So we have a trend with random variation; an ideal case for Trend Surface Analysis.
The next example concerns a nickel ore-body disseminated in peridotite, which has been 'proved' by means of about 45 vertical boreholes. The average spacing between the boreholes was about 60m and they were not regularly spaced, so that only the 'down-the-hole' experimental semi-variograms were calculated.
Altogether approximately 4000m of core was recovered and assayed in 2m core sections. In this case the logarithm of the grades was used, rather than the grades; the reason for this has no relevance here. The experimental semi-variogram is shown in Fig 2.14, and the numerical values are given in Table 2.8.

Fig 2.14. Experimental
semi-variogram for a nickel deposit − logarithms of grade values.
Table 2.8 Experimental semi-variogram from a
disseminated nickel deposit (logarithm of grade)
|
|
|
There appears to be a definite flat sill at about 2.55(log %)2. However, drawing a straight line through the first two points, as we did in the silver semi-variogram produces two odd results. First, the line intersects the semi-variogram axis at 0.40(log%)2 not at zero. This suggests that there is a component of each value which is 'random' or unpredictable. Samples very close together still have a reasonably large difference in value. Remembering that the sill (if it exists) is equal to the sample variance, we can see that 0.40/2.55=0.156� suggests that about 16% of the variation in the sample values is random and unpredictable. Thus, no matter how closely we sample, this unpredictability will still exist. The semi-variogram model will need to be of the form:

where γ(h) is the usual sort of model (e.g. linear). In effect, the nugget effect is a simple constant raising the whole theoretical semi-variogram 0.4 units. Thus we now seek a model with a sill of 2.15(log %)2. Now, we saw in the silver example that extending the initial straight line slope up to the sill gave a value of two-thirds of the range of influence, when using a spherical model. In this case the intersection produces a value of 13m implying a range of influence of about 20m. On the other hand, the curve does not even approach the sill until some distance past 45m. Clearly neither of our ideal models will cope with this sort of situation. Let us look again at the experimental curve. There seems to be an 'intermediate' sill, reached at about 14m and a value on the γ-axis of 1.95 − 0.40 = 1.55 (to allow for nugget effect). We seem to have a mixture of two spherical type models, one with a shortish range and one with a range of about 50m. Let us try out this tentative model and see how it fits the experimental semi-variogram. We have a fairly complex model:

Putting these values into the proposed model produces the following:
![]()
For distances (h) between 14 and 50m, the model is given by:
![]()
and when the distance between the two samples is greater than 50m, the model semi-variogram takes the form:
![]()
In order to compare the theoretical model with the experimental points we must evaluate the model at various distances, and draw the resulting curve onto the same graph. For example, for distance h equal to 2m:
![]()
and for a distance h equal to 40m:
![]()
A set of values was selected for h and the theoretical curve constructed. The values are shown in Table 2.9, and the resulting model has been plotted in Fig 2.15. The experimental points are also shown for comparison.
|
|
Table 2.9 First
attempt to fit a mixture of Spherical models to the experimental nickel semi-variogram (parameters in text)
|
The 'model' curve fits fairly well to the beginning and end of the experimental semi-variogram, but does not seem too good in the middle. The kink in the curve is at far too high a level − it needs to occur at γ=1.95.
We assumed that this level was equal to C0+C1. What was forgotten is that, even at short distances, the second spherical component still contributes some value to the model, so that the value 1.95 should actually be equal to:
![]()
In other words, we need to lower the value of C1 and raise the value of C2, and then try the fit again. After a few tries, I got the following model:

This model is shown in Fig 2.16 alongside the experimental semi-variogram, and seems to be a relatively good fit. Perhaps the reader would like to try to improve upon it? Table 2.10 gives the corresponding numerical values for the model curve.
|
|
Table 2.10 Final attempt to fit a mixture of Spherical models to the experimental Nickel semi-variogram (parameters in text)
|
Examples of semi-variogram models which are mixtures of spherical components abound in the geostatistical literature, and seem to be about the most common type encountered, especially in low concentration minerals such as cassiterite, copper veins, uranium and so on.
* * * * * *
I should like, now, to turn to another problem which is often discussed in the literature when samples are expected to follow a log-normal distribution. Whilst the construction of the experimental semi-variogram and the estimation procedures produced by geostatistics do not depend on what distribution the samples follow, there are one or two 'side-effects' which become apparent when dealing with log-normal samples. As every schoolboy knows, the standard deviation of a log-normal distribution is directly proportional to its mean. Consequently the sample variance − and hence the sill of the semi-variogram − is proportional to the square of the mean of the samples. If experimental semi-variograms are constructed on different sets of samples within a deposit, this 'proportional effect' can have a radical effect on the individual experimental semi-variograms. Examples in the literature usually concern cases where, in order to construct experimental semi-variograms in different directions, it has been necessary to use different sets of, e.g. borehole data in each. As an example of 'proportional effect' consider the following situation. In Cornish tin lodes the assay values are usually assumed to follow a log-normal distribution. Such veins are developed by means of horizontal drives approximately 100ft apart. These drives are sampled every 10ft by taking chip samples from the roof. In the example under consideration, nine levels have been developed, from 600ft below surface to 1400ft (6-14 levels). Semi-variograms were calculated for each level separately. For simplicity, Fig 2.17 shows only three of these experimental semi-variograms, for levels 6, 10 and 12. The other six lie scattered between levels 6 and 12. Figure 2.18 shows a graph of the average assay value along each drive versus the standard deviation of the samples along that drive.

Fig 2.17. Example of
supposed zonal anisotropy − cassiterite vein.

Fig 2.18. Illustration
of the proportional effect − cassiterite.
The averages vary between 35lb/ton (pounds of SnO2 per ton of ore) and 80lb/ton, and the standard deviations vary between 35 and 110lb/ton. The relationship is virtually perfect between the two, with a calculated correlation coefficient of over 0.85. Since the sill of the semi-variogram is roughly equal to the calculated sample variance, it is easy to see that the experimental semi-variogram for level 6 will be (and is) the lowest, with a sill of about 1200(lb/ton)2; level 10 will be in the middle with a sill of about 5000; and 12 will be the highest with a sill of 12000(lb/ton)2. The question is, can we make an overall semi-variogram for this deposit when the individual experimental semi-variograms vary by an order of magnitude from area to area.
The published authorities state that the valid way to combine these semi-variograms is to 'correct' each one for the proportional effect. That is, to divide the individual experimental semi-variograms by the square of the average of the samples which went into its calculation. This produces a 'relative semi-variogram' − implying that all values given by the semi-variogram are now 'relative to the local mean'. Applying this method to the above example results in nine experimental relative semi-variograms which vary in sill between about 1.00 and 1.80. Notice that these values now have no units. To be converted into meaningful figures they must be multiplied by the square of the local mean. We can now (supposedly) combine these semi-variograms into one for the deposit as a whole, and fit a model to it. If we do so we must remember that in all our estimation procedures etc. we have to 'uncorrect' the values calculated from the semi-variogram − estimation variances, standard errors and so on.
This process of correcting experimental semi-variograms for the proportional effect is widely advocated as the 'right thing to do'. No one seems to have bothered to test whether it actually works in practice. In the one case, that described above, where I have been able to investigate in depth and compare what happens if you use the 'relative' semi-variogram, I found that correction by the local mean gave completely erroneous results. Therefore, I would not recommend this procedure, but rather that you should combine the original experimental semi-variograms and try to fit a model to the 'uncorrected' data. In the study mentioned above this was found to give the correct values at all times.
* * * * * *
It has been said time and again that geostatistics − Kriging and so on − can be applied equally well to other variables which are spatially or temporally distributed. This book has been more or less devoted to mining applications, because this is still the major field. However, many other variables can be handled, and I should like to give one or two examples here. Even in mining applications, grade or economic value of the mineral is not always the sole variable of interest. In many deposits the 'thickness' of the deposit is as important as the grade, and in many sedimentary deposits this factor is far more important. In the Cornish tin example described above, the width of the vein is fully as important a variable as the cassiterite content. Both variables are required to assess the economic viability of the lode or portions of it. Figure 2.19 shows the overall experimental semi-variogram calculated for the nine levels, 6-14. To this semi-variogram I fitted a model which consisted of: a small nugget effect, which was slightly surprising; one spherical component with a range of influence of about 30ft and another with a range of 150ft.

Fig 2.19. Experimental semi-variogram constructed on the lode widths in the cassiterite vein.
As an example of other types of spatially distributed data which might be considered, Fig 2.20 shows an experimental semi-variogram which was produced during a study of the rainfall characteristics and runoff in a catchment area in the Pennines in England.

Fig 2.20. Experimental semi-variogram constructed on the measured rainfall at rain gauge sites.
The data observations are the recorded monthly rainfall figures at rain gauges scattered over the catchment area. The semi-variogram has been constructed without regard to the direction of the pair of samples. That is, the author has assumed that his variable shows the same continuity down the long axis (direction of flow of the major river) as it does across the valley. The erroneous nature of this assumption is immediately apparent when given the information that the catchment area measures about 30km across the valley (short axis). The marked discontinuity in the experimental curve suggests that there is a definite difference between the two major directions. Semi-variograms ought to be constructed for at least two different directions to check for this. The second conclusion which can be drawn from this experimental semi-variogram is that if the same shape is shown by the new individual strong trend is in evidence which must be taken into consideration. When considering the nature of rainfall it does seem sensible to expect different amounts of rain to fall on the tops of mountains than lower down in the valleys. This is a good example of when the 'trend' cannot be ignored in the geostatistical estimation procedure.
And now for a completely different type of application we can take a time series example, rather than one which is spatially distributed. A series of readings have been taken at the same site in a large river, of various different variables of interest. This is a 'one-dimensional' situation, in which the dimension is time rather than space. Instead of distance between samples, we now have time between samples, so that the horizontal axis of the experimental semi-variogram will now read 'time between observations'. The estimation procedure will be used to predict values of these variables forward into the future, or to fill in gaps in the records caused by machine failure. Figure 2.21 shows two experimental semi-variograms calculated in one case for the temperature of the water, and in the other for the amount of suspended solids contained in the water. The latter looks like an ideal case for a spherical type of model, with a suggestion of a 'trend' at the weekly scale i.e., fairly homogeneous within any specified week, but varying in level from week to week. The experimental semi-variogram for the temperature shows a perfect daily cycle in temperature, with a little drift coming in after 3 or 4 days.

Fig 2.21. Experimental
semi-variograms calculated on water quality variables measured over time.
To summarise this chapter, we have seen how to calculate an experimental semi-variogram in one and two dimensions, and how to relate this 'practical' semi-variogram to the 'ideal' models which exist. We have seen that, whilst some deposits may follow fairly simple behaviour, many others require a fairly complex mixture of models to describe the experimental semi-variogram. I have briefly pointed out some problem areas such as strong trends, random phenomena and proportional effect, and tried to indicate how these might be tackled. There are those in authority who say that the fitting of a semi-variogram model is out-moded and unnecessary. To counter this I should like to give an analogy with ordinary statistics. If you take a limited number of samples from an exceedingly large population and construct a histogram, are you prepared to assume that that sample histogram describes exactly the behaviour of the whole population? The process of inference − drawing conclusions about the population from a few samples − demands the construction of some sort of model for the behaviour of the whole deposit.
. + . + . + .
In the previous chapters we have discussed semi-variograms, calculated experimental semi-variograms and fitted models to these as if the samples had no characteristics other than 'position'. We have ignored the size and shape of the sample, the way in which it may have been taken and/or measured, and so on. We have effectively assumed that the sample values were located at 'points' within the deposit. In this chapter we will see what effect those other characteristics − collectively called 'support' − have on the sample value itself, and hence on the semi-variogram.
Let us consider the lead/zinc example which was discussed in Chapter 2. Although the cores were actually 1.52m long, we ignored this fact and calculated the experimental semi-variogram as before. Suppose, however, that the cores had been sectioned into 3.04m lengths instead of 1.52m − what effect would this have on the sample values and on the semi-variogram? Table 3.1 shows the 'borehole log' for 1.52 and for 3.04m samples. The experimental semi-variogram was also calculated for the 3.04m cores, with the results shown in Table 3.2.

Fig. 3.1. Experimental semi-variograms constructed on various lengths of core − lead/zinc example.
Figure 3.1 shows the 'new' experimental semi-variogram alongside the 1.52m one for comparison. For good measure, both
tables and the figure also show the resulting values for cores of 4.56m. It can be seen immediately that the 3.04m semi-variogram is always lower than the 1.52m, and the 4.56m one is considerably lower than both. Let us return to the basic assumptions of Geostatistics and try to explain this behaviour. We must recall two facts from Chapter 1. The first is the basic definition of the semi-variogram: it is the average square of the difference in grade between two samples a given distance apart. If those samples were 'points' then the grade is assumed to be measured 'at a point'; if they are cores then the grade measured is the average grade over the core length. Thus we are not comparing two individual grades, e.g. g1 and g2, we are comparing two average grades ![]() 1 and
1 and
![]() 2. We cannot reasonably expect the average grade over 1.52m of core to have the same behaviour as the grade of a 'teaspoonful' of ore. Similarly, if we take the grade and average it over 3.04m
we would expect different behaviour again. The question is how to characterise this difference in behaviour.
2. We cannot reasonably expect the average grade over 1.52m of core to have the same behaviour as the grade of a 'teaspoonful' of ore. Similarly, if we take the grade and average it over 3.04m
we would expect different behaviour again. The question is how to characterise this difference in behaviour.
The second fact to recall from Chapter 1 is that the sill of the semi-variogram − if one exists − is equal to the ordinary sample variance. If we are dealing with 'point' samples, then we can estimate the sill of the semi-variogram, and compare this value with the sill. That is, C=s� (ideally).
Now, if the samples are cores of a certain length l (e.g. 1.52m) and we measure the average grade over that length, then we have smoothed out some of the 'point' variation. We have replaced a large number of individual 'points' with one average value. The variance of the averages will therefore be less than the variance of the 'points', so that
In a similar way C3.04 will be less than C1.52 and so on. If we have a model for the semi-variogram for the point samples we could produce the model for any other size of sample, by employing the mathematical relationship between the point model (γ) and the model for samples of length l (γl). Since we are only using a limited number of simple models for the point semi-variogram, it is not too difficult to state this relationship.
If we have a linear model for the point samples, γ(h)=ph, where p is the slope of the semi-variogram line, then the semi-variogram for samples of length l is given by:

This is illustrated in Fig. 3.2, with the point model for comparison.

Fig. 3.2. Regularisation of a linear
semi-variogram by core lengths.
In practice, we generally have an experimental semi-variogram for samples of length l, that is γl*, and we need to find the model for the point samples (γ)�for use in the later chapters. Since the slope, p, of the core model is the same as that of the point model, simply measuring the slope of our experimental γl* will give a value for p, and hence the point model, γ. One complication arises if the point model is actually a linear model plus a nugget effect. Taking core samples lowers the line, but a nugget effect will raise it again. From the above formula, if no nugget effect is present, extending the line of the core model back until it intersects the semi-variogram axis should produce an intercept of −pl/3. Once an estimate of p has been made this can easily be checked, and if necessary a nugget effect C0 added to the model.
Now suppose our deposit followed an exponential model, with sill C for 'point' samples, i.e.
![]()
For cores of length l, the theoretical model becomes:
![]()
with a rather more complex form for distances less than the length of the core (h<l). Since we are unlikely to have values of an experimental semi-variogram for distances less than the sample length, the form of it seems rather academic. Figure 3.3 shows a point exponential model and the corresponding 'regularised' curve for a sample of length l. It can easily be seen that Cl is lower than C. In fact:
![]()
so that a sample which was, say, one-fifth of the range of influence, would produce a sill:
![]()
That is, the new sill will only be 94% as high as that of the point model. It will also be noticed from Fig. 3.3 that extending the 'linear' part of the core model (close to the origin) until it intersects the sill produces an estimate of the range of influence for the cores al, which is longer than that of the points, a.

Fig. 3.3. Regularisation of an exponential
semi-variogram by core lengths
In fact, al = a+l. This seems quite sensible if you remember that cores will have to be just that bit further apart before they become independent.
The above arguments and formulae apply to the situation where you know the 'point' model and you wish to find the 'regularised' model. In practice the situation is generally reversed. We usually have an experimental semi-variogram which has been calculated on cores of a given length, and we need to find the point model for use in the estimation techniques. Suppose, then, that we have a graph of the experimental semi-variogram γl*, and we have decided that our deposit follows an exponential model. The first step is to guess the two parameters Cl and al. Since the model is exponential, the sill Cl will be greater than most of the experimental points on the graph. Having guessed Cl, produce a line up through the first two or three points on the graph until it cuts the sill. This will give a first guess at al. We know that a=al−l, so we have a first estimate of a. Using this in the above formula for Cl, we can reverse the equation and produce a value for C, the point sill. We now have guesses at the values of a and C which govern the point model. The next question is whether these are 'good' guesses. We have already stated that if we know the point model, we can produce the corresponding model for cores of any given length, i.e. γl(h). If our guesses are good ones then this theoretical model for γl(h) should match the experimental semi-variogram, γl*(h). Substituting values for h, l, a and C produces a smooth curve like the lower one in Fig. 3.3, and this can be compared to the data. If necessary, a and C can be altered until the 'model' values become a good fit to the 'data' values. In effect, this is the same procedure as was used in Chapter 2, but with an additional consideration of the sample length.
Let us now turn to the most common model − the spherical model. This will be influenced in the same sort of way as the exponential. The sill for the cores will be lower than that for the 'points', and:

The formula for the semi-variogram of the cores is extremely complex because of the 'discontinuity' in the model but an example is shown in Fig. 3.4. A subroutine to evaluate the formula has been published. If the calculations are to be done by hand (or hand calculator) then it is easier to use tables such as Table 3.3.

Fig. 3.4. Regularisation of a
spherical semi-variogram by core lengths.
This table shows the form of the 'regularised' semi-variogram for a core of length l if the original point semi-variogram had a range of influence a, and a sill of 1. The use of this table is best illustrated by an example. We can now return to the example shown in Fig. 3.1 of the zinc values measured over core lengths of 1.52m. In Chapter 2 we guessed that the sill lay at about 10.5(%)�. This is our first approximation of Cl. Producing the line through the first two points on the experimental semi-variogram gives 2al ÷ 3 = 9.6m (approximately). That is, al = 14.4m, and hence a = 12.9m. Using the formula:

The first estimates, then, for the parameters of the point model are a = 12.9m and C = 11.2(%)�. We must find the row in the Table 3.3 which corresponds to our value of a/l, i.e. 8.5. The entries along this line correspond to multiples of the sample length l. That is, h/l = 1 means h = 1.52m, h/l = 2 means h = 3.04m and so on. We see that at h/l = 1 the table gives a value of 0.116. This would be for a semi-variogram with a sill of 1. Since we have a sill of 11.2(%)�, the value we require is 0.116 × 11.2 =1.30(%)�. This is now a 'model' value for the semi-variogram of cores of length 1.52m and can be plotted on the graph next to the 'observed' value of 1.33(%)�.
A second point on the model would be at h = 3.04m, i.e. h/l = 2. The table gives a value of 0.288 for C = 1, so that our model value is 0.288 × 11.2 = 3.23(%)�. This can be compared with the experimental value of 3.09(%)�. This process is repeated until we have a model value to compare with each observed value. The resulting model curve has been plotted in Fig. 3.5. This seems to be rather a good fit to the experimental semi-variogram, if we accept the sill at 10.5(%)�.

Fig. 3.5. Fitted regularised model
to the lead/zinc example − 1.52m cores.
Adjustments could be made if the sill was thought to be too low, by raising C and a. Suppose we accept this 'point' model with a = 12.9m and C = 11.2(%)�. We can run a secondary check by comparing the models for core lengths 3.04m and 4.56m. For the former, a/l = 4.25 so that we must interpolate in the table between a/l = 4.00 and a/l=4.50. Linear interpolation is generally sufficient for this sort of exercise. Figure 3.6 shows the experimental and model curves for each sample length, and the point model for comparison.

Fig. 3.6. Fitted models to the
lead/zinc example − 3.04m and 4.56m cores and the 'point' model.
The model seems to be a good fit to the 3.04m semi-variogram, especially to the first four points. However, after the first point on the 4.56m semi-variogram the model here is consistently considerably higher than the experimental semi-variogram until h is about 41m. This could perhaps be neglected in view of the fact that each of these experimental values is calculated on 15 or fewer pairs. All in all, the spherical model as estimated seems to be a pretty good fit.
This process of the semi-variogram changing with different 'support' is usually known in the literature as 'regularisation' − on the basis that the samples get more regular as the sample size increases. We have seen that we can handle experimental semi-variograms for core samples, and still derive the supposed point model. However, this leads us on to another problem of the 'volume−variance' relationship and the influence of sample size on the sort of distribution encountered. Suppose at the pre-feasibility stage of investigating a deposit the management requests a grade/tonnage calculation.
That is, given an economic cutoff grade (or list thereof) can we evaluate (i) the tonnage of ore in the deposit which is above cutoff and (ii) the average grade of that ore. Suppose we take an example to illustrate the problem which arises. A hydrothermal tin vein has been sampled by means of nine development drives approximately 100ft apart in the plane of the lode. Chip samples are taken every 10ft along these drives. The sampling setup is shown in Fig. 3.7.

Fig. 3.7. Typical sampling situation
in Cornish tin example.
These chip samples may be considered as 'points' since they have a very small volume. Figure 3.8 shows a histogram of the 2730 chip samples taken from the development drives in this lode. Suppose we now specify a 'cutoff grade' of 25lb/ton for this lode. The histogram shows that about 44% of the chip samples lie below 25lb/ton. We could (possibly) make the statement that we therefore believe that 44% of the ore in the lode lies below 25lb/ton.

Fig. 3.8. Histogram of chip samples
taken from the drives in the cassiterite vein
Now, the usual method of estimating the value in the stopes is to delineate a block (say 125ft long) between the drives and allocate to that block the average of all the peripheral development samples. It is this estimate which determines whether a stope block enters 'reserves' or not. Figure 3.9 shows the corresponding histogram of the estimates of 125ft by 100ft stoping blocks, i.e. the averages of the drive samples over two lengths of 125ft each.

Fig. 3.9. Histogram of estimates of
stope values in the cassiterite vein.
We have seen from the previous exercise that we expect averages over lengths to be somewhat less variable than 'point' samples. This is adequately borne out by the behaviour of these estimates. Whereas the point values range up to 300lb/ton or more, the drive averages seldom exceed about 150lb/ton. Whilst 44% of the point samples lie below 25lb/ton something less than 8.5% of the 'block estimates' do so. Should we now say that 8.5% of the ore lies below 25lb/ton? What we really need to do is to redefine the phrase 'of the ore'. In the first case what we meant was that if the deposit were divided into chip samples, we could reject 44% of these as being below cutoff. In the second it was 8.5% of the drive averages below cutoff. That is, if the deposit were divided into pairs of 125 ft strips 100ft apart, 8.5% of these would be below cutoff. Or alternatively, by my estimate 8.5% of the stope blocks would be below cutoff. In other words, we cannot define how much ore we have after selection unless we define a unit of selection in terms of size and shape. The real question is 'how many 125 by 100ft stope panels are below cutoff?' To answer this question we must determine what sort of distribution these panels would follow. The full answer will depend on (i) the distribution of the original samples and (ii) the semi-variogram of the deposit.
Let us make a general statement of the problem and see how it leads to a solution. The original sample data has a 'support' of, say, l; it has a semi-variogram
γl(h) with a sill Cl; it has a distribution of grades which can to some extent be characterised by the histogram and which has a mean
![]() l and variance Cl. The panels or blocks being estimated will have a support of, say, v; a semi-variogram γv(h) with sill Cv; a distribution with mean
l and variance Cl. The panels or blocks being estimated will have a support of, say, v; a semi-variogram γv(h) with sill Cv; a distribution with mean
![]() v and variance Cv. The first thing we can say is that
v and variance Cv. The first thing we can say is that ![]() l and
l and
![]() v should be the same, since both describe the average grade of ore over the whole deposit. Thus we can replace them both by
v should be the same, since both describe the average grade of ore over the whole deposit. Thus we can replace them both by
![]() , the average of 'point' samples. The second thing we can say is that if we have a model for the point semi-variogram we can state the
relationship between the point sill C and the 'core' sill Cl, and between C and
Cv for any defined volume v. Suppose we take the simple example of a core of length l which can be represented as a straight line (since the diameter is very much smaller than the length).
, the average of 'point' samples. The second thing we can say is that if we have a model for the point semi-variogram we can state the
relationship between the point sill C and the 'core' sill Cl, and between C and
Cv for any defined volume v. Suppose we take the simple example of a core of length l which can be represented as a straight line (since the diameter is very much smaller than the length).

Fig. 3.10. Derivation of the variance of grades within a 'line' segment.
This is illustrated in Fig. 3.10. Consider two points on this line, M and M'. We could calculate from the model semi-variogram the 'difference' between the grades at these two points. Now suppose we took all possible pairs (M,M')� which exist within the line − including the case when M=M'. In this way we could get a measure of the 'variability' of the grades within the line. If we take the average of the semi-variogram values γ(M−M') over all possible pairs, then we obtain the variance of the grades within the length l.
This is the variance which is removed from the system if we only consider the average grade over the length l, i.e. the difference between the point sill and the regularised sill, C−Cl. Mathematically:
![]()
where F(l) defines the variance of grades within the length l. Although this looks fearsome, it reduces to:
![]()
for the linear model
![]()
for the exponential model, and for the spherical model:
![]()
![]()
These, of course, correspond exactly with the difference between the point and regularised semi-variograms. Now suppose we want to consider a two-dimensional panel such as that shown in Fig. 3.11.

Fig. 3.11. Derivation
of the variance of grades within a panel.
The F function now becomes F(d,b) �to show that it has two dimensions. This would be a quadruple integral, since the points M and M' can now move throughout the whole panel. The formulae get complicated, but not impossible, and for example of the type of values encountered, Table 3.4 has been produced. This table shows the F(d,b)� function for a spherical model with range equal to 1 and sill of 1. This is a 'standardised' spherical model − in the same sense as a 'Standard' Normal distribution. This table can be used to produce the corresponding value of the F function for any spherical model, as follows:
i. divide the lengths of the sides of the panel by the range of influence a;
ii. read off the corresponding entry in the table;
iii. multiply this value by C.
Examples of such calculations are given later in this chapter. Similar tables may be produced for the linear and exponential models.
In three dimensions the problem of calculating the F(l,b,d) function analytically appears to be insurmountable. It is necessary to resort to a numerical approximation using a computer. The easiest way to do this is to go back to the definition of the F function: we take pairs of points (M,M') within the block; consider all such pairs; calculate the semi-variogram value between M and M'; sum all these values and average them − this gives the F value. Now, suppose we do not take all of the pairs but only a few 'representative' ones. That is, instead of considering the block as an infinite number of points we consider it to be a 'grid' containing a finite number of points, say on a 5 by 5 by 5 grid. Some authors suggest taking 'randomly' distributed points, but there seems little sense in that. Using such a method, Table 3.5 was produced for the 'standardised' spherical model. In order to produce only one table, it has been necessary to insist that two sides of the block have the same length. This table is used in the same way as the two-dimensional one.�
So, we now know how to calculate the function F for one, two and three dimensions, and hence can state the difference between the 'point' variance and the 'regularised' variance of regular shaped areas and volumes. This will give us a numerical quantity for the reduction in the variance, but unless we make some assumptions about the distribution of the samples, we cannot actually quantify the change in the 'tonnage above cutoff' and so on. There are two ways to approach the problem:
i. Assume that the histogram of the samples represents the whole deposit accurately.
ii. Assume that the histogram represents a set of samples from the whole deposit, and as such contains some random variation from the 'population' distribution.
The first approach declares that the samples are 'typical' of the whole deposit, and leads to graphical anamorphisms and transfer functions. The second approach declares the belief that if we could measure the grade at every point in the deposit we would end up with a smooth curve of a fairly simple form. This is a much simpler approach, and generally seems to be sufficient for most deposits.
To start with a simple example, let us consider an iron ore deposit which is known to follow a Normal distribution with a mean of 48%Fe and a standard deviation of 5%Fe. This distribution has been established on samples small enough to be called 'points'. We also know that the deposit follows a point semi-variogram model which is spherical with a range of influence of 400ft. Now, suppose that the mine plan is to be constructed on blocks which are 100ft by 100ft by 50ft. What will the distribution of these blocks look like. The first thing we can say is that it will probably be Normally distributed. It will certainly have the same mean (48%Fe)� as the 'points'. The only change will be in the standard deviation of the distribution. We need to evaluate the function F(100,100,50) for a spherical model with a = 400 and C = 25. To use Table 3.5 we must 'standardise' the situation so that the range of influence becomes 1. That is, F(100,100,50)� for a=400 is the same as F(0.25,0.25,0.125) for a=1. Table 3.5 gives a value of 0.209 for these arguments, but this is for a model whose sill is 1. For our model the required value is 0.209×25=5.225(%Fe)�. This is the difference between the point variance and the block variance. Therefore the variance of the block values will be 25−5.225=19.775(%)��leading to a block standard deviation, sv, of 4.45%Fe. This is slightly over 10% less than the point standard deviation, as would be expected with such a 'small' block. Thus we have two distributions to be considered, both Normal, as follows:
i. point distribution:
![]() = 48%Fe, s = 5%Fe
= 48%Fe, s = 5%Fe
ii. block distribution: ![]() v = 48%Fe, sv
= 4.45%Fe
v = 48%Fe, sv
= 4.45%Fe
These two distributions are shown in Fig. 3.12, and the reduction in spread for the block distribution can be clearly seen.

Fig. 3.12. Comparison of the distributions of points and blocks within a hypothetical iron ore deposit.
To see how the difference in the distributions will affect the grade−tonnage calculations, let us take as an example a cutoff grade of 44%Fe.
The proportion (P) of the distribution which is above cutoff is given by:
P = Pr{g > c}
where g denotes the grade in general, and c the cutoff grade. Tables are widely available for the Standard Normal distribution, which tabulate the proportion of the Standard Normal distribution which lies below a given value z. For any other Normal distribution the z value is determined by taking the value of interest, subtracting the mean of the distribution, and dividing by the standard deviation. In our example, we are considering the cutoff grade, c, so that
![]()
The Normal table will give us Φ(z), which is the probability of lying below the cutoff, so that
![]()
Thus, if we consider the distribution of the 'point' values, we obtain the following:

Consulting a Standard Normal table gives Φ(z)=0.212 so that P=0.788. That is, about 79% of the deposit will lie above a cutoff of 44%Fe. The second question is the average grade of this ore. For the Normal distribution, the grade above cutoff is given by:
![]()
where ![]() c denotes the grade above cutoff, and φf(z) is the height of the standard normal curve at the value z, i.e.
c denotes the grade above cutoff, and φf(z) is the height of the standard normal curve at the value z, i.e.
![]()
For our example, then, φ(z)=0.290 so that:
![]()
To summarise, 78.8% of the ore lies above a cutoff of 44%Fe, and this ore has an average grade of 49.8%Fe.
Let us repeat this exercise, but now taking into account the 'selective mining unit' of 100ft x 100ft x 50ft. We have:

The Standard Normal table gives φ(zv)=0.184 so that P is now 0.816, and the average grade above cutoff is
![]()
Although the differences in this example are not substantial, it can clearly be seen that if the selection is applied to the average grade of 100ft by 100ft by 50ft blocks, then the tonnage mined (the proportion of the deposit) is larger and the grade of the ore is lower than would be expected from the original samples. If the cutoff grade chosen were above the mean grade of the deposit, the position would be reversed. This is not merely an academic observation, but is borne out by experience on many mines in existence.
Now let us turn to a much more common situation, in which the grade distribution is log-normal. Take as an example a lead/zinc deposit, where the 'combined metal' percentage is the economic variable. The samples are known to be log-normally distributed, and the mean and standard deviation of the 'point' samples are 12% and 8% combined metal respectively. The semi-variogram is spherical with a range of 15m. The 'selective mining unit' is a block 10 by 10 by 5m. Using Table 3.5, we can find that F(10,10,5)� when a=15 and C=64 is given by 0.516 ÷ 64 = 33.034. This produces a block standard deviation of 5.56% combined metal. The two distributions are compared in Fig. 3.13.

Fig. 3.13. Comparison of the distributions of
combined metal percentages within a hypothetical lead/zinc deposit.
To calculate the proportion above cutoff and the average grade of the ore for a log-normal distribution requires an extra step in the proceedings. By definition, if a variable has a log-normal distribution, then the logarithm of that variable has a Normal distribution. It is necessary to calculate the mean and standard deviation of this Normal distribution before we can perform any calculations. If we write y for the logarithm of the grade, then the mean and standard deviation of the y values are given by:

Once these parameters have been calculated, then the following may be evaluated:

where P is again the proportion of the ore above cutoff. The average grade is found by the following process:
![]()
where Q=1−Φ(z−sy).
In the lead/zinc example above, 4% combined metal is a feasible cutoff grade. Considering the 'point' distribution then:

The original sample data informs us that 93.4% of the deposit lies above 4%(Pb+Zn) and that this ore has an average value of 12.62% combined metal. Now, considering the distribution of 10 by 10 by 5m blocks, the following results are found:

Once again, selection made on a mining block unit, this time of size 10 by 10 by 5m, produces a larger tonnage and a lower grade than the small samples would suggest. Table 3.6 shows the resulting values when a set of possible cutoff values is chosen. Figure 3.14 shows the resulting grade/tonnage curves in the normal manner employed in mining reports. The one minor difference here is that 'proportion' above cutoff is given rather than tonnage, to keep the example general. The 'bias' introduced by considering 'point' samples rather than the true selective mining unit can clearly be seen on this graph.
 |
|
|||||||||||||||||||||||||||||||||||
| Fig. 3.14. Comparison of grade/tonnage curves in the lead/zinc deposit. |
Table 3.6 Comparison of grade/tonnage calculations for point and block values for combined metal (Lead/Zinc) deposit |
|||||||||||||||||||||||||||||||||||
Here is a very brief example with which to finish off. A low grade uranium deposit has a log-normal distribution with mean 0.30% U3O8 and a standard deviation of 1.05% U3O8. The spherical semi-variogram has a range of 40m, and the selective mining unit has a size of 25 by 25 by 10m. Using Table 3.5 gives an F function of 0.477 ÷ 1.1025 = 0.526, producing a standard deviation for the blocks of 0.76% U3O8. Table 3.7 shows the results of applying cutoffs of 0.05, 0.10, 0.15 and 0.20% U3O8 to (i) the 'point' samples and (ii) the block distribution.
Table 3.7. Comparison of grade/tonnage
calculations for point and block values for uranium deposit
|
POINTS |
BLOCKS |
||
|
proportion |
average grade |
proportion |
average grade |
Cutoff |
above cutoff |
|
above cutoff |
|
0.05 |
0.622 |
0.47 |
0.712 |
0.41 |
0.10 |
0.452 |
0.62 |
0.527 |
0.53 |
0.15 |
0.355 |
0.75 |
0.414 |
0.64 |
0.20 |
0.291 |
0.88 |
0.337 |
0.75 |
Figures 3.15 and 3.16 illustrate these results. Notice how the skewed nature of the original distribution, and the relatively large size of the block combine to produce an ever widening gap between the point curve and the block curve.
|
|
|
|
Fig. 3.15. Comparison of point and block grade/tonnage curves in a uranium deposit − cutoff grade versus proportion above cutoff. |
Fig. 3.16. Comparison of point and block grade/tonnage curve in a uranium deposit − cutoff grade versus average grade. |
In this chapter we have considered the problems introduced by the volume, size, shape etc. of both samples and selective mining units. We have seen how the 'point' semi-variogram model may be derived, even though the experimental semi-variogram may have been constructed on samples with a definite support. We have also seen how, for certain regular shapes, the distribution of values changes according to the support of the selective mining unit. The construction of 'theoretical' grade/tonnage curves can be achieved providing the following information is available:
i. the distribution of the 'point' values;
ii. the semi-variogram of the 'point' values;
iii. the size and shape of the selective mining unit.
In this way more 'realistic' first estimates of the grade/tonnage calculations may be produced at a very early stage in any study.
. + . + . + .
So far we have used the basic concepts and assumptions of Geostatistics to build ourselves a 'model' of the structure and continuity within the deposit. We have also (in Chapter 3) seen how this can lead to the production of 'theoretical' grade/tonnage curves and the study of how mining block size can influence final production Figures. It is now time we returned to our original problem of the estimation of ore reserves. The discussion in this (and the next) chapter will be confined to 'local' estimation, i.e. interest is confined to one portion of the deposit at a time. However, it should be borne in mind that the same techniques can be applied on a global scale, i.e. to the whole deposit at once. It should also be remembered that block-by-block or stope-by-stope estimates will lead inevitably to global estimates.
Let us, then, define the situation which is of interest to us. There is a point or an area or a volume of ground over which we do not know the grade (or value), but we wish to estimate it. Let us call this 'unknown' grade T, and the area (or point, or volume) of interest A. In order to produce an estimator we must have some information, usually in the form of samples. To be completely general, let us suppose n samples with values of g1,g2,g3...gn. This set of samples is generally denoted by S. From these samples we can form a 'linear' type of estimator − that is, a weighted average. We must restrict ourselves to this type of estimator at this stage. The estimator is denoted by T* and is equal to:
![]()
where the w1, w2, w3...wn are the weights assigned to each sample. Most currently used local estimation techniques use a weighted average approach − inverse distance techniques and so on. The simplest case of all is when all of the weights are the same, and T* is just the arithmetic mean of the sample values.

|
|
||||||||||||||||||||||||||||||||
|
Fig 4.1. Hypothetical sampling and estimation situation − a uranium deposit. |
Table 4.1 Positions
and values on hypothetical Uranium estimation problem |
Now consider the setup of samples and 'unknown' which we originally discussed in the first chapter. Figure 4.1 shows the point of interest which lies at position A, and we have five 'point' samples lying around this position. The co-ordinates of these six points and the values of the samples are given in Table 4.1. The hypothetical deposit is a low-grade, large-tonnage uranium one, which is assumed to be isotropic. The semi-variogram model fitted to this deposit is a spherical one with a range of influence of 100 ft, a sill value (C) of 700 (p.p.m.)2 and a nugget effect of 100 (p.p.m.)2. Let us take the simplest possible estimation procedure. Take the value at the closest sample position (1) and 'extend' this to the unknown point. In doing so we incur an estimation error, ε, which will be equal to the difference between the actual value T and the estimated value T*, which in this case equals g1. That is:

It is not too difficult to show that if there is no trend (at least locally), this estimator is unbiased. That is, if we make lots of similar estimations the average error will be zero.
![]()
The 'reliability' of the estimation can be measured by looking at the spread of the errors. If the errors take values consistently close to zero, then the estimator is a 'good' one. If the spread of values is large, then the estimator will be unreliable. The simplest stable measure of spread (statistically) is the standard deviation. The standard deviation of an estimation error − or standard error as it is referred to in ordinary statistics − will therefore measure the reliability of that estimator.
No matter how many estimations we perform, we cannot calculate the standard deviation of the errors since we do not know the value of the error made. Therefore we must look at the 'theoretical' form of the variance of the estimation error, i.e. the estimation variance:

The average would be made (theoretically) over the whole deposit. That is, the same estimation situation would be repeated over the whole deposit and the variance found. This cannot be done in practice, of course, so let us look closer at the form of this variance. It is found by taking the grade at point A, subtracting the grade at point 1, squaring the result, repeating the process over all possible pairs of such points and then averaging the values. This sounds exactly like the definition of a variogram. In fact, it is the variogram between the two points A and (1). Given the distance between them (h)�we can evaluate this estimation variance simply by reading a value from the semi-variogram model (γ)�and multiplying it by 2. This is one of the reasons why it is good policy to avoid confusing the variogram and the semi-variogram. Thus:
![]()
In the case of our particular example given in Fig. 4.1:

Given our knowledge about this deposit, i.e. the semi-variogram model, we can state (without too much fear of error) that the estimator used has a standard error of 25.4 p.p.m. Turning this standard error into a confidence interval, however, requires the assumption of some kind of probability distribution for the deposit. For instance if we hope that the Central Limit Theorem holds, we can say that a 95% confidence interval for T would be given by T* ± 1.96 σε, i.e. (350 p.p.m., 450 p.p.m.). On the other hand, if we were to assume a log-normal distribution for the errors, the 95% confidence interval would be given by (354 p.p.m., 453 p.p.m.).

Fig. 4.2. More realistic estimation − the
value of the block is required (uranium deposit).
Now, let us complicate the procedure a little. Instead of estimating the value at the point A, in a more realistic situation (at least in mining) we would be interested in the average grade over an area or block or some mining unit. In Fig. 4.2, a 'panel' 60 ft by 30 ft has been centred on the original point A. The estimation procedure then becomes:

The same arguments as previously still hold. The average
error can be shown to be zero if there is no local trend. The estimation variance is still a variogram, but it is now the variogram between the grade at sample point (1) and the average grade over the panel A. We saw in Chapter 3 that we could cope with average grades over samples if we wanted the semi-variogram between samples of the same size, but so far we have not considered the possibility of
having two different sizes to compare. The model semi-variogram supplies us with the difference in grades between two points. We could find the value of the semi-variogram between the sample point and every point within the panel
A, and we could average those values. Let us define
this quantity as ![]() (S,A), read as 'gamma-bar between the sample and every point in the panel'. The 'bar' notation is the standard one for arithmetic mean. This gamma-bar term will take the place of the γ(h)
in our previous relationship. However, what we really need is the semi-variogram between the average grade of panel
and the sample, not between all the individual points within the panel and the sample − 2
(S,A), read as 'gamma-bar between the sample and every point in the panel'. The 'bar' notation is the standard one for arithmetic mean. This gamma-bar term will take the place of the γ(h)
in our previous relationship. However, what we really need is the semi-variogram between the average grade of panel
and the sample, not between all the individual points within the panel and the sample − 2![]() (S,A)
would be the variance of the error made if we tried to estimate every point within the panel. To correct for this
difference in emphasis we need to take into account the variation of the grades at points within the panel.
(S,A)
would be the variance of the error made if we tried to estimate every point within the panel. To correct for this
difference in emphasis we need to take into account the variation of the grades at points within the panel.
This was discussed in Chapter 3, and we evaluated it using the auxiliary function F(l,b). This was the average semi-variogram between all possible pairs of points within the panel. We can rewrite this in a more general way using the gamma-bar notation. That is, ![]() (A,A) will be the average semi-variogram value between every point in the panel and every point in the panel. In the case shown in Fig. 4.2, then, when using the value at sample point (1) to estimate
the average grade of the panel, the estimation variance becomes:
(A,A) will be the average semi-variogram value between every point in the panel and every point in the panel. In the case shown in Fig. 4.2, then, when using the value at sample point (1) to estimate
the average grade of the panel, the estimation variance becomes:
![]()
The calculation of these gamma-bar terms will be discussed more fully later.
Now, let us complicate the mathematics still further. We actually have more than one sample available to us, so why not use them in the estimation procedure. Suppose we use the arithmetic mean of the samples as our T*. This gives us the simplest form of the weighted average type of estimator. That is:

In this case the term ![]() (S,A) is the average semi-variogram value between each point in the 'sample set' S and each point in the panel A. The term
(S,A) is the average semi-variogram value between each point in the 'sample set' S and each point in the panel A. The term
![]() (A,A) is still the average semi-variogram between each point in the panel and each point in the panel. However, now we have yet another source of spurious variation. We only consider the average
grade of the samples as the estimator, but
(A,A) is still the average semi-variogram between each point in the panel and each point in the panel. However, now we have yet another source of spurious variation. We only consider the average
grade of the samples as the estimator, but ![]() (S,A)
takes the individual grades into account. Thus we have
also to subtract a
(S,A)
takes the individual grades into account. Thus we have
also to subtract a ![]() (S,S)term from the variance, where this is the average semi-variogram value between each point in the sample set and each point in the sample set (i.e. 25 'pairs' of samples). The final version of the estimation variance then becomes:
(S,S)term from the variance, where this is the average semi-variogram value between each point in the sample set and each point in the sample set (i.e. 25 'pairs' of samples). The final version of the estimation variance then becomes:
![]()
The arithmetic mean is often known in Geostatistics as an extension estimator, and the above variance is referred to as the extension variance. To distinguish this variance from the more general estimation variance for a weighted average, the subscript e is used rather than the general ε.
CALCULATION OF GAMMA-BAR TERMS
Having produced a formula for the extension variance, it only remains to explain how to calculate such terms as
![]() (S,A) in practice. For the sake of our (too) simplistic approach, we will consider for the moment only simple idealistic cases, and these only in one or two dimensions. Generalisation will be discussed later.
(S,A) in practice. For the sake of our (too) simplistic approach, we will consider for the moment only simple idealistic cases, and these only in one or two dimensions. Generalisation will be discussed later.

Fig.4.3. Example of using a peripheral point to estimate the average value of the
line segment.
Consider, as an example, the setup in Fig. 4.3. There is a length of, say, drive, l m long, whose grade is unknown.
We have at our disposal a single sample, perhaps at a development heading, whose value is known. In our previous notation T is the average grade over l, T* is the grade at the sample position, A is the length and S is the single sample point. The reliability of this estimator is given by:
![]()
![]() (S,S) is the semi-variogram between the sample point and itself, which is zero because the sample is a 'point'.
(S,S) is the semi-variogram between the sample point and itself, which is zero because the sample is a 'point'.
![]() (A,A) is none other than the F(l) function encountered in Chapter 3. Our
problem arises with
(A,A) is none other than the F(l) function encountered in Chapter 3. Our
problem arises with ![]() (S,A) which has been defined as the average semi-variogram between the sample point and every point in the line. That is, we take M as a fixed point (the sample) and M' can be anywhere on the line. We
take all such pairs that are possible, calculate the value of the semi-variogram for each pair, sum these (using an integration), and average this sum. Because the 'sum' is being performed over a continuous length, we cannot divide it by the 'number of points' in the sum. Instead we divide by the
length of the line itself, l. This produces another auxiliary function which is called χ(l) and deals with the specific case of points on the end of lines. Thus our extension variance becomes:
(S,A) which has been defined as the average semi-variogram between the sample point and every point in the line. That is, we take M as a fixed point (the sample) and M' can be anywhere on the line. We
take all such pairs that are possible, calculate the value of the semi-variogram for each pair, sum these (using an integration), and average this sum. Because the 'sum' is being performed over a continuous length, we cannot divide it by the 'number of points' in the sum. Instead we divide by the
length of the line itself, l. This produces another auxiliary function which is called χ(l) and deals with the specific case of points on the end of lines. Thus our extension variance becomes:
![]()
It remains only to determine the function χ(l) for the particular model in use and the standard error is immediately available. The one-dimensional auxiliary functions are given below for the three 'common' models. Semi-variograms comprising more than one component model are easily handled. The auxiliary function for each component is evaluated and then the component auxiliary functions added together.
Auxiliary functions
Linear model for the semi-variogram;

Exponential model for the semi-variogram;

Spherical model for the semi-variogram:

Thus in our example above, if we have a linear semi-variogram, the extension variance for the setup in Fig. 4.3 becomes:
![]()
For any specific problem, we need specify only the length of the line l and the slope of the semi-variogram, p.
Let us now consider a slightly more interesting example, such as that shown in Fig. 4.4.

Fig 4.4. Example of using a central point to
estimate the average value of the line segment.
Here the point sample is in the middle of the line, but otherwise the situation remains the same. In:
![]()
only the first term ![]() (S,A) has changed. Rather than invent a new auxiliary function, or have to do the integration all over again, we can use the existing χ(l) function to produce the required term.
(S,A) has changed. Rather than invent a new auxiliary function, or have to do the integration all over again, we can use the existing χ(l) function to produce the required term.
The term we require is as follows:
|
|
=� the average semi-variogram value between the sample point and every point along the line = (sum of all semi-variogram values between the sample point and every point along the line)/l = (sum of all the semi-variogram values between the sample point and every point in the left hand half of the line + sum of all the values between the sample and the right hand half of the line)/l |

Fig 4.5. Simplifying the central point problem
to allow the use of auxiliary functions.
Figure 4.5 illustrates the 'splitting' of the line so as to put the sample point at the end of two shorter lines. Now, χ(l/2) would give us the average of all the semi-variogram values between M (the sample point) and the M' on the left hand half of the line. Returning to the definition of the χ function, it can easily be seen that the sum of all the semi-variogram values between M and M' will be the average multiplied by the length of line under consideration.
Thus:
![]()
so that
![]()
In a particular case the user may substitute his own model for the semi-variogram, and hence the appropriate auxiliary functions. Before moving on let us compare this result with the previous situation, where the sample lay at the end of the line. In the former case the extension variance was:
![]()
By definition χ(l) must be greater than (or at least equal to) χ(l/2). The conclusion? If you can only take one sample, it is better to take it in the middle of what you are trying to estimate. It is reassuring to find that so-called common sense has a sound mathematical background.

Fig. 4.6 Generalisation of the 'central' point problem.
Using the same sort of logic on Fig. 4.6, you should be able to deduce that:
![]()
so that
![]()
Figure 4.7 at first sight seems to be a different kettle of fish. However, let us follow the same procedure and see where it leads.

Fig. 4.7. Extrapolation of the peripheral point problem.
The point lies on the end of a 'line' of length l+b. The expression (l+b) χ(l+b) would give us the sum of all the semi-variogram values between the sample and the length l+b. However we do not require the points corresponding to M' within the length b, so we may subtract those in the form b χ(b). That is:
![]()
so that
![]()
For the linear model, for example, this would be:

This is obviously larger than the expression when the point was on the end of the line, as would be expected.
One last example before we abandon one-dimensional examples: Fig. 4.8 shows the 'same' line, which now contains three samples.

Fig. 4.8. More complex problem when three samples are available to estimate the line segment.
We shall use the arithmetic mean of the three grades to estimate the length, i.e. T*=(g1+g2+g3) � 3. Then our extension variance is
![]()
where S is now a set of three points.
![]() (A,A) remains unchanged, equal to F(l) since we have not changed the length to
be estimated at all. However,
(A,A) remains unchanged, equal to F(l) since we have not changed the length to
be estimated at all. However, ![]() (S,A) is now the average semi-variogram value between each of the three points and the line, so that
(S,A) is now the average semi-variogram value between each of the three points and the line, so that
![]()
where S1 represents sample 1 and so on. Now
![]() (S1,A) is simply χ(l), as is
(S1,A) is simply χ(l), as is
![]() (S3,A). The term
(S3,A). The term ![]() (S2,A) is the same situation as that in Fig. 4.4, so this equals
χ(l/2). Thus,
(S2,A) is the same situation as that in Fig. 4.4, so this equals
χ(l/2). Thus,
![]()
The middle term of the variance
![]() (S,S) requires us to take each point in the sample set with each point in the sample set. Since there are three points in the set, there are nine such pairs of points:
(S,S) requires us to take each point in the sample set with each point in the sample set. Since there are three points in the set, there are nine such pairs of points:

Each of the individual terms is simply the semi-variogram between a pair of points. Three of the terms, γ(S1,S1), γ(S2,S2) and γ(S3,S3) are automatically zero since the samples are points. The terms γ(S1,S2), γ(S2,S1), γ(S2,S3) and γ(S3,S2) are all equal to γ(l/2), whilst γ(S1,S3) and γ(S3,S1) are equal to γ(l). Thus:
![]()
so that
![]()
For our linear example, this reduces to:

This is considerably less than the other evaluations, as seems only sensible with three times as many samples.
In two dimensions we have again a set of auxiliary functions which are mostly generalisations of the one-dimensional ones. These are shown in Fig. 4.9.

Fig. 4.9. The two-dimensional auxiliary functions.
γ(l;b) is the two-dimensional analogue of γ(l) − sometimes read as γ(l) stretched through length b. It is the average semi-variogram value between all points on one length, b, and all points on another parallel to it and of the same length. This function is useful for parallel boreholes, channel samples, drives, raises and so on. The generalisation of χ(l) becomes χ(l;b) and is the average semi-variogram between a length b (drive, raise, core etc.) and an adjacent panel l by b. The function F(l,b)�has been introduced in Chapter 3
for such terms as ![]() (A,A) for rectangular panels. We also introduce a 'new' function H(l,b)
which does duty for two rather different situations. It represents the average semi-variogram value between a panel and a point on one corner of it; it also
represents the average semi-variogram value between two lengths l and b at right angles to one another.
This is simply a mathematical accident.
(A,A) for rectangular panels. We also introduce a 'new' function H(l,b)
which does duty for two rather different situations. It represents the average semi-variogram value between a panel and a point on one corner of it; it also
represents the average semi-variogram value between two lengths l and b at right angles to one another.
This is simply a mathematical accident.
A few examples will be given here to show how to 'manoeuvre' situations into the required form. Figure 4.10 shows a stoping panel in a cassiterite vein, 100 ft by 125 ft, with a development drive passing through it parallel to the sides. The drive is 25 ft from the 'bottom' of the panel.

Fig. 4.10. Estimation of the panel average from the drive average.
The drive is so closely sampled that we can assume we know its average grade. We wish to use that average grade as an estimate of the average grade of the panel, so that:

![]() (A,A) is the average semi-variogram value between every point in A and every point in A, which is the definition of the two-dimensional function F(l,b). Thus if we have a model for the semi-variogram we can evaluate this. Let us suppose that in the above example the semi-variogram is a spherical model with a range of influence of 80 ft and a sill of 450 (lb/ton)2. The table given in Chapter 3 for the
F(l,b)�function (Table 3.4) is for the 'standardised'
spherical model with a = 1 and C = 1. We require
F(125,100)� for a model in which a = 80 and
C = 450. To convert to a = 1 we divide the measurements l and b by the range a (80 ft). Thus we require F(125/80,100/80) =
F(1.54,1.20) for a = 1 and C = 450. From the table (interpolating linearly) we find that
F(1.54,1.20)=0.7807 when C = 1. Therefore, if
C = 450, our F value must be 0.7807\450=351.3 (lb/ton)2. This finally is
(A,A) is the average semi-variogram value between every point in A and every point in A, which is the definition of the two-dimensional function F(l,b). Thus if we have a model for the semi-variogram we can evaluate this. Let us suppose that in the above example the semi-variogram is a spherical model with a range of influence of 80 ft and a sill of 450 (lb/ton)2. The table given in Chapter 3 for the
F(l,b)�function (Table 3.4) is for the 'standardised'
spherical model with a = 1 and C = 1. We require
F(125,100)� for a model in which a = 80 and
C = 450. To convert to a = 1 we divide the measurements l and b by the range a (80 ft). Thus we require F(125/80,100/80) =
F(1.54,1.20) for a = 1 and C = 450. From the table (interpolating linearly) we find that
F(1.54,1.20)=0.7807 when C = 1. Therefore, if
C = 450, our F value must be 0.7807\450=351.3 (lb/ton)2. This finally is
![]() (A,A).
(A,A).
Now let us consider the term
![]() (S,S). Our sample is a 'line' of length 125 ft, and the
(S,S). Our sample is a 'line' of length 125 ft, and the
![]() (S,S) is the average semi-variogram value between every point in the line and every point in the line, i.e. the one-dimensional function
F(l). For a spherical semi-variogram model, where the length is greater than the range of influence, we know that:
(S,S) is the average semi-variogram value between every point in the line and every point in the line, i.e. the one-dimensional function
F(l). For a spherical semi-variogram model, where the length is greater than the range of influence, we know that:
![]()
Substituting the values l = 125 ft, a = 80 ft and C = 450 (lb/ton)2, gives
F(125) = 270.9 (lb/ton)2, and this is the value used for ![]() (S,S).
(S,S).
Finally, we must turn to ![]() (S,A) which presents a problem, since the auxiliary function χ(l;b)
is only for situations where the 'line' is on one side of the panel. We must employ the same sort of manoeuvre as before:
(S,A) which presents a problem, since the auxiliary function χ(l;b)
is only for situations where the 'line' is on one side of the panel. We must employ the same sort of manoeuvre as before:
|
|
= average semi-variogram value between the line and a panel 125 ft � 100 ft. = (sum of the semi-variogram values between the line and the panel) � (100 � 125) =(sum of the semi-variogram values between the line and the points in the 'upper' panel + sum of the semi-variogram values between the line and the points in the 'lower' panel) � (100 � 125) |
However, the average semi-variogram value between the line and the 'upper' panel (125 � 75 ft) is given by χ(75;125), so that the sum of the semi-variogram values between the line and every point in the upper panel will be 75 × 125 × χ(75;125). Similarly, the sum of the semi-variogram values between the line and every point in the 'lower' panel (125 ft × 25 ft) will be given by 25 × 125 × χ(25;125). This gives:

Table 4.2 shows the values of the χ(l;b)
function for the 'standardised' spherical model with
a = 1 and C = 1. This table is used in the same
way as the F(l,b) table. It should be noted that the order of the arguments is important. The value of
χ(25;125) is obviously different from the value of
χ(125;25). Standardising the measurements of the panel in the same way as before, we require the values of
χ(0.94;1.54) and χ(0.31;1.54)
from the table. Interpolating linearly gives the values 0.8196 and 0.6538 respectively. Multiplying by the sill of 450
(lb/ton)2 gives 368.8 (lb/ton)2 and 294.2 (lb/ton)2 respectively. Putting these
together in the expression for
![]() (S,A) gives a value of
350.2(lb/ton)2.
(S,A) gives a value of
350.2(lb/ton)2.
Having evaluated all of the individual terms, we can now calculate the extension variance for the setup in Fig. 4.10, so that:
![]()
This gives an estimation standard deviation or 'standard error' of 8.8 lb/ton for the estimation of the panel grade. If we are willing to assume Normality for the errors (sic) we could be 95% certain that the 'true' grade of the panel lay between T* ± 2 σe equal to T* ± 16.6 lb/ton. This standard error would be correct for any panel having the same sampling setup, anywhere within this deposit, since the estimation variance depends not on the actual grades involved but on the geometric positioning of the sample and the panel.

Fig. 4.11. Estimation of the panel average from two drive averages.
As a second example, consider a disseminated nickel deposit in the late stages of development. On a particular underground level, we have a stoping block 40m by 30m to be estimated. If we consider only the one level we can treat the problem as a two-dimensional one. Suppose this 'panel' has been developed along two sides, and the information available consists of (i) the average grade along the 40m drive, g1 and (ii) the average grade along the 30m drive, g2. Suppose we use the average of these two grades to estimate the value inside the panel. Then:

For this particular deposit we have a spherical semi-variogram with a range of influence of 60m, a sill of 0.75(%)2 and a nugget effect of 0.10(%)2. This implies a standard deviation for the 'point' sample values of 0.92%. The extension variance, as always, is given by:
![]()
![]() (A,A) is, as before, the two-dimensional function F(l,b), but now we have two components to the evaluation of this term. We can calculate the F(40,30) for the spherical part of the model, with
a = 60m and C = 0.75(%)2. This turns out to be 0.4336 � 0.75=0.325(%)2. To this we must add the nugget effect of 0.10(%)2, so that
(A,A) is, as before, the two-dimensional function F(l,b), but now we have two components to the evaluation of this term. We can calculate the F(40,30) for the spherical part of the model, with
a = 60m and C = 0.75(%)2. This turns out to be 0.4336 � 0.75=0.325(%)2. To this we must add the nugget effect of 0.10(%)2, so that ![]() (A,A) = 0.425(%)2.
(A,A) = 0.425(%)2.
The average semi-variogram value between each sample and each sample now contains four terms which have to be averaged, i.e.:

It is generally easier to look at each term separately and
then to combine them to produce the final answer. The first term ![]() (drive1, drive1) is the average semi-variogram between all points within a length of 40m. That is,
F(40).
(drive1, drive1) is the average semi-variogram between all points within a length of 40m. That is,
F(40).
For a spherical model, when the length of the 'line' is shorter than the range of influence, F(l) is given by:
![]()
Substituting l = 40 and a = 60, C = 0.75(%)2 gives a value of 0.239 (%)2. Adding on the nugget effect produces
![]() (drive1,
drive1) = 0.339(%)2. Similarly,
(drive1,
drive1) = 0.339(%)2. Similarly, ![]() (drive2,
drive2) = 0.283(%)2. The two terms
(drive2,
drive2) = 0.283(%)2. The two terms
![]() (drive1,
drive2) and
(drive1,
drive2) and ![]() (drive2,
drive1) are identical and have been defined as the auxiliary function H(l,b). Using Table 4.3 for the
H(l,b) function in the same way as the other tables
and adding in the nugget effect gives:
(drive2,
drive1) are identical and have been defined as the auxiliary function H(l,b). Using Table 4.3 for the
H(l,b) function in the same way as the other tables
and adding in the nugget effect gives:
![]()
Putting all the individual terms together, we find that ![]() (S,S) = 0.428 (%)2.
(S,S) = 0.428 (%)2.
Finally, to calculate the estimation variance, we also
require the term ![]() (S,A). This is the average semi-variogram value between each sample and the panel, so that:
(S,A). This is the average semi-variogram value between each sample and the panel, so that:

The extension variance for the problem illustrated in Fig. 4.11 is thus:
![]()
giving a standard error for the prediction of the panel average of 0.376% nickel.
A third example is shown in Fig. 4.12.

Fig. 4.12. Estimation of the panel average from two raise averages.
This time the metal is zinc, the semi-variogram is spherical with a range of 20m and a sill of 49(%)2. The value to be estimated is the average over the 30m by 15m panel, and the information available is the average grade of each of the two raises through the 'stope panel'. In the idealised situation chosen, the raises are both 7.5m from the edges of the panel. Very briefly, the extension variance is produced as follows:

The term ![]() (A,A) = F(30,15)
when a = 20 and C = 49(%)2, which is 0.7021 × 49 = 34.4(%)2.
(A,A) = F(30,15)
when a = 20 and C = 49(%)2, which is 0.7021 × 49 = 34.4(%)2.

The γ(l;b) function is given for the 'standardised' spherical model in Table 4.4. The last term to be evaluated is:
![]()
Since the setup is symmetrical, ![]() (raise1,A) =
(raise1,A) =
![]() (raise2,A), so that
(raise2,A), so that

This gives an extension variance of:
![]()
This gives a standard error for the estimation of the panel average of 1.14% Zn. Thus although the original sample standard deviation for 'point' samples was 7% Zn, two 'samples' within the panel produce a standard error one-sixth of this figure.
One last brief example: a porphyry copper deposit has been explored by means of vertical boreholes. To simplify the problem, each 'bench' in the deposit is considered separately as a plane, and the borehole intersections as points within the plane. Take a typical small block, 25m by 25m, with a borehole passing through it as shown in Fig. 4.13.

Fig. 4.13. Estimation of panel average from one 'point' sample.
Suppose we 'extend' the value of the core intersecting the block to the whole block. Then:

Then
![]()
From previous investigation we know that the semi-variogram
has a spherical form with a range of influence of 90m and a sill of 0.6(%)2 Cu.
![]() (A,A) is yet another
F(25,25) function, whose value can be calculated to be
0.2145 � 0.6 = 0.129(%)2 Cu.
(A,A) is yet another
F(25,25) function, whose value can be calculated to be
0.2145 � 0.6 = 0.129(%)2 Cu. ![]() (S,S) = 0 since the sample is supposed to be a point.
(S,S) = 0 since the sample is supposed to be a point. ![]() (S,A) must be calculated with the now familiar(?) manoeuvring, as follows:
(S,A) must be calculated with the now familiar(?) manoeuvring, as follows:

So, finally, the extension variance becomes:
![]()
so that the standard error for the estimation is 0.288 %Cu. The same exercise can be repeated for a sample outside the panel, using the same logic as that applied to the one-dimensional problem in Fig. 4.7.
1. When an estimation is performed, an error is made in the prediction.
2. The magnitude of that error is dictated by the structure and type of the deposit, and by the mineral itself. Different minerals within the same deposit may have different structures.
3. The structure can (probably) be described by a semi-variogram model, in the absence of significant trend on the local level.
4. The estimation error variance can be calculated if the semi-variogram model is known. Tables for the spherical model have been supplied. These may also be used as approximations for the linear model.
5. If we use the extension type of estimator, i.e. the arithmetic mean of the samples, then the extension variance may be written:
![]()
That is, the 'reliability' of the estimator depends on three quantities: the relationship of the samples to the area to be estimated; the relationship amongst the samples; and the variation of grades within the area being estimated.
Let us return to the original problem posed in Figs. 4.1 and 4.2. We showed that if we used the grade of sample 1 to estimate the point A, we obtained a standard error of 25.4 p.p.m. We then introduced the problem of estimating a 60 ft by 30 ft block centred at A. After the examples above, it should be easy enough to calculate that the extension standard error will now be 19.2 p.p.m. [![]() (S,A)=356,
(S,A)=356, ![]() (A,A)=344,
(A,A)=344, ![]() (S,S)=0] , when estimating the average grade of the panel from the single sample point 1. This is over 20% lower than when trying to estimate the central point. The real conclusion is simply that it is easier to estimate the average grade over a block than to specify the grade at a single point. Now, if we consider the arithmetic mean of the 5 point-samples, we obtain the following:
(S,S)=0] , when estimating the average grade of the panel from the single sample point 1. This is over 20% lower than when trying to estimate the central point. The real conclusion is simply that it is easier to estimate the average grade over a block than to specify the grade at a single point. Now, if we consider the arithmetic mean of the 5 point-samples, we obtain the following:

If we use this estimator to predict the central point of the block, the extension standard deviation is 21.8 p.p.m. However, if we estimate the panel, the extension standard deviation reduces to 12.8 p.p.m. Notice that both of these Figures are lower than when only considering sample 1. It would appear that, even though the other samples are a lot further away from the centre of the block, they are contributing a fair amount of information about the block grade.
To conclude this chapter, an example on a slightly grander scale, on which the reader can exercise his new-found knowledge. For this deposit a simulation has been used, since in that case we know the semi-variogram and the value at every point within the deposit. This enables us to compare estimates with 'actual' values − a situation which is rare to the point of extinction in the real world. It also enables us to produce a set of samples on any given sampling scheme proposed. The simulated deposit is a low grade sedimentary iron ore, with an overall average of about 35% Fe, a standard deviation of 5% Fe, a range of influence of 100m and a sill of 25(%)2 Fe − obviously. The semi variogram is spherical (yet again) with no nugget effect. An area 400 metres square has been simulated and a set of 50 samples taken from it at random. The positions and values of these are shown in Fig. 4.14 and Table 4.5.

Fig 4.14. A set of
random samples taken from a simulated iron ore deposit
The initial estimation, at the pre-feasibility stage, is to be done on 50m by 50m blocks. For this first example, each block has been allocated the average grade of all interior samples. Where a sample falls on the edge it has been allocated to both blocks. Figure 4.15 shows the estimated value for each block.

Fig 4.15. Estimates
of block values formed by averaging all interior samples in the iron ore deposit, and the corresponding extension standard deviations.
Blocks without internal sampling have been shaded in. The upper Figure shown in each block is the estimator T*, and the lower is the extension standard deviation. Since this deposit is actually Normally distributed, 95% confidence limits would be given (approximately) by T* ± 2 σe. For comparison, the 'true' average grade for each block is shown in Fig. 4.16.

Fig 4.16. 'Actual' average values within each block in the simulated iron ore deposit.
It can be seen that in most of the 37 estimated blocks, the true value is within the 95% confidence interval. Four or five blocks lie just outside the interval, and three or four are considerably outside. This is a little higher than would be expected, since we would only expect about two blocks to lie outside a 95% interval. However, if we consider the 99% confidence interval (3 standard deviations) only one block is significantly outside the interval, i.e. the lower left-hand block of the area (south-west corner).
For comparison, Fig. 4.17 shows a set of samples taken on a regular grid from the same 'deposit'. In this case, each 50m block has two samples in opposing corners.

Fig 4.17. A set of samples taken on a regular grid from the simulated iron ore deposit.
Using the average of these two samples to estimate the block results in an extension standard deviation of 2.5% Fe, Fig. 4.18 shows the estimated values in each block.

Fig 4.18 Estimated
block values from regular samples.
It can be seen that although five or six blocks lie outside the 95% confidence interval, not one lies more than 2.25 standard deviations from the true value.
Having exhausted the possibilities of extension in idealised circumstances, let us move on to some more interesting situations.
. + . + . + .
![]()
where the weightings sum to 1. If this condition is met, and there is no trend (locally) then T* is an unbiased estimator. This means that over a lot of estimations the average error will be zero. This type of estimator is called a 'linear' estimator because it is a linear combination of the sample values. The arithmetic mean is simply a special case where all of the weights are equal. It can be shown that the estimation variance for the general 'unbiased linear' estimator is:

Where we previously calculated ![]() (S,A) which was the average semi-variogram
between each sample and the unknown area, we now form a weighted average for
each individual sample with the area A,
(S,A) which was the average semi-variogram
between each sample and the unknown area, we now form a weighted average for
each individual sample with the area A, ![]() (Si,A), in the same way as the actual estimator.
For example, if we have n samples taken around the area A, the first term in
the variance becomes:
(Si,A), in the same way as the actual estimator.
For example, if we have n samples taken around the area A, the first term in
the variance becomes:

The last term in the variance, ![]() (A,A), does not change its form, since we have only changed
the form of the estimator, not the area being estimated. The term
(A,A), does not change its form, since we have only changed
the form of the estimator, not the area being estimated. The term
![]() (S,S)
which previously measured the variation
in values between the samples, must now take into account the different weights
associated with each sample. Thus, if we take, e.g., sample 4 we must remember
that it has a weight w4. If we take sample 4 with, say,
sample 2, then we must include both weights w2 and w4,
so that the term becomes
(S,S)
which previously measured the variation
in values between the samples, must now take into account the different weights
associated with each sample. Thus, if we take, e.g., sample 4 we must remember
that it has a weight w4. If we take sample 4 with, say,
sample 2, then we must include both weights w2 and w4,
so that the term becomes
w2 w4 ![]() (S2,S4)
(S2,S4)
To form the equivalent ![]() (S,S), then, each
(S,S), then, each ![]() (Si,Sj) is multiplied by the corresponding
wiwj before being added into the sum.
(Si,Sj) is multiplied by the corresponding
wiwj before being added into the sum.

Fig. 5.1. Three samples to be used to estimate the line segment.
As a simple example, let us consider the setup in Fig. 5.1. We calculated the extension variance for this setup in Chapter 4. The arithmetic mean gave an extension variance of pl/18 when we used a linear semi-variogram with the form γ(h) =ph. Now suppose we allocate a set of weights to these three samples instead of treating them all the same. Let us, for this example, put three-quarters of the 'weight' at the central point, and an eighth on each end point. The 'new' estimator is therefore:

The reliability of this estimator will be given by the general form of
σε2. The term ![]() (A,A) is given by the function
F(l), by definition, which for the linear semi-variogram takes the form
pl/3. The central term − the 'within samples' term − is:
(A,A) is given by the function
F(l), by definition, which for the linear semi-variogram takes the form
pl/3. The central term − the 'within samples' term − is:

where each sample is taken with each sample in turn −
including itself − and the combination is multiplied by both weights. Since
the samples in this case are all points, all the ![]() (Si,Sj)
terms can be found directly from the semi-variogram γ(h). This gives:
(Si,Sj)
terms can be found directly from the semi-variogram γ(h). This gives:

Since the semi-variogram model is linear, this becomes:

This leaves only the first term − the between sample and area term − to be evaluated. This is:
![]()
Sample 1 is at one end of the length l, so that
![]() (S1,A) =
χ(l). Similarly
(S1,A) =
χ(l). Similarly ![]() (S3,A) = χ(l). Sample 2 is the central point of the
length l, so that
(S3,A) = χ(l). Sample 2 is the central point of the
length l, so that ![]() (S2,A) = χ(l/2). For the linear model
χ(l) =pl/2, so that
(S2,A) = χ(l/2). For the linear model
χ(l) =pl/2, so that

Putting all these together, gives an estimation variance of:

The specified set of weights, (1/8, 3/4, 1/8) when used with a linear semi-variogram model give an estimation variance of 0.0729pl. The arithmetic mean of the samples gave an extension variance of pl/18=0.0556pl, which is three-quarters of the size of the estimation variance above. It is fairly obvious in this case that the specified weighted average gives a worse estimator than simply using the arithmetic mean.

Fig. 5.2. Estimation of the block
value is required from the five scattered samples − uranium example
As a two-dimensional example, let us return to the ubiquitous uranium example as illustrated in Fig. 5.2. We shall allocate weights to each sample according to its distance from the centre of the block A. Table 5.1 shows the 'inverse distance' calculation for the weights in this example.
Table 5.1. Calculation of Inverse Distance
weightings for hypothetical Uranium estimation problem
| Sample | Distance from | Inverse | Corrected |
| number | centre (ft) | distance | weight |
| 1 | 21.54 | 0.0464 | 0.319 |
| 2 | 50.00 | 0.0200 | 0.137 |
| 3 | 31.62 | 0.0316 | 0.217 |
| 4 | 30.00 | 0.0333 | 0.229 |
| 5 | 70.00 | 0.0143 | 0.098 |
| Total | 0.1457 | 1.000 |
The estimator T* becomes:

The three terms which go into the variance are:

The individual values of ![]() (S1,A)
and so on are the same as those evaluated
when considering the extension variance, and are equal to 356.7, 572.4, 456.9,
446.8 and 696.1 respectively. Thus the first term in the variance is equal to
461.9 (p.p.m.)2 − as opposed to 505.8 (p.p.m.)2 in the
extension variance. The second term in the
variance of the weighted mean turns out to be 441.2 (p.p.m.)2. In the
extension case it was 504.7 (p.p.m.)2. The final term in both variances is
344.0 (p.p.m.)2 as given by the auxiliary function F(l,b).
Putting these Figures together gives us
an estimation variance for the inverse distance estimator of 138.6 (p.p.m.)2.
This is equivalent to a 'standard error' of 11.8
p.p.m. Thus, using the inverse distance weights we obtain an estimate of 372.8
p.p.m. U3O8 for the panel, and we can say that this has a
standard error of 11.8 p.p.m.,
which has been derived from our knowledge of the semi-variogram of this
deposit. If we are willing to make the additional assumption of Normality of
the errors, we could say that a 95% confidence interval for the 'true' value of
the panel is (349 p.p.m., 396 p.p.m.). This should be compared to the extension
estimate of 366 p.p.m., with a standard error of 12.8 p.p.m., and a 95%
confidence interval of (340 p.p.m., 392 p.p.m.). It can quickly be seen that
the inverse distance estimation produces a (slightly) more accurate result than
the arithmetic mean − this seems quite sensible.
(S1,A)
and so on are the same as those evaluated
when considering the extension variance, and are equal to 356.7, 572.4, 456.9,
446.8 and 696.1 respectively. Thus the first term in the variance is equal to
461.9 (p.p.m.)2 − as opposed to 505.8 (p.p.m.)2 in the
extension variance. The second term in the
variance of the weighted mean turns out to be 441.2 (p.p.m.)2. In the
extension case it was 504.7 (p.p.m.)2. The final term in both variances is
344.0 (p.p.m.)2 as given by the auxiliary function F(l,b).
Putting these Figures together gives us
an estimation variance for the inverse distance estimator of 138.6 (p.p.m.)2.
This is equivalent to a 'standard error' of 11.8
p.p.m. Thus, using the inverse distance weights we obtain an estimate of 372.8
p.p.m. U3O8 for the panel, and we can say that this has a
standard error of 11.8 p.p.m.,
which has been derived from our knowledge of the semi-variogram of this
deposit. If we are willing to make the additional assumption of Normality of
the errors, we could say that a 95% confidence interval for the 'true' value of
the panel is (349 p.p.m., 396 p.p.m.). This should be compared to the extension
estimate of 366 p.p.m., with a standard error of 12.8 p.p.m., and a 95%
confidence interval of (340 p.p.m., 392 p.p.m.). It can quickly be seen that
the inverse distance estimation produces a (slightly) more accurate result than
the arithmetic mean − this seems quite sensible.
Suppose we change the situation slightly. Suppose that sample 3 was not north of the block but south, i.e. northing 2310, as in Fig. 5.3.

Fig. 5.3. Sample 3 is now located South of the block to be estimated.
The inverse distance weights are unchanged, because they depend on the distance between the sample and the block centre.
However, the estimation standard error rises sharply to 14.3 p.p.m., indicating a loss in accuracy. The change in the estimation variance is caused solely by a decrease in the size of the 'within samples' term − the amount of information contained in the sample set − since the other two terms remain the same as before. In actual Figures the term falls from 441.2(p.p.m.)2 to 376.2(p.p.m.)2. It does not really seem very sensible to use the same weights for Fig. 5.3 as we did for Fig. 5.2, since sample 3 now gives us a lot less 'information' than it did previously. We could suggest a new set of weights and calculate the estimation variance. If this were smaller than the 'inverse distance' set, we could say our 'new' estimator was (in some sense) better than the inverse distance one. Alternatively, we could use a different method to produce the weights − inverse distance squared, for example. It would seem a lot more desirable to find a direct method of producing the 'best' estimate, given our knowledge of the deposit.
We have decided to use a 'linear' type of estimator − a weighted average of the sample values. We know that it is an unbiased estimator if the weights add up to 1. There is an infinite number of such linear unbiased estimators, so we will search for the 'best' one, and we will define 'best' as 'having the smallest estimation variance'. The expression for the estimation variance depends on three things: the basic geometry of samples and unknown area, the form of the semi-variogram, and the weighting allocated to each sample. For any given setup the variance can only be changed by altering the values of the weights. Thus we wish to minimise the estimation variance with respect to the weights. The variance is a simple (?) function of the weights, so to minimise it we must differentiate and set the differential equal to zero:
![]()
This will provide n equations in n unknowns (w1, w2, w3, w4...wn). These weights will provide an estimator which has the minimum value of the estimation variance. However, they will not necessarily add up to one. There is nothing in the above system of equations that constrains the weights in this way. Effectively, we also need to satisfy the equation Σwi=1. Thus, to obtain the 'Best Linear Unbiased Estimator' we actually have to satisfy (n+1) equations. However, we only have n unknowns, so far, which is not a very desirable condition. To rectify this we must introduce another unknown, in the form of a Lagrangian Multiplier, to balance up the system. Therefore, instead of minimising the estimation variance, we actually minimise:
![]()
with respect to w1, w2, w3, w4 wn, and λ. This last produces the equation:
Σ wi � 1 = 0
as is required. After the differentiation has been performed and the equations tidied up, the following system results:

Although this looks slightly fearsome in its complexity, if
you look a little closer, you will find that most of the elements are (I hope)
by now familiar to you. Consider the first equation. The right hand side merely
requires the average semi-variogram value between sample 1 and the unknown
area. The left hand side contains the n+1 unknowns, wi
and λ, and the average semi-variogram
value between sample 1 and each of the other samples in turn. All of these
![]() terms are identical to those which we would
work out for an extension or an estimation variance.
terms are identical to those which we would
work out for an extension or an estimation variance.
The second equation is identical to the first except that it is sample 2 which is present right along the equation. The third has sample 3 all the way along, and so on until the nth equation with Sn all the way along. Finally, we have the necessary condition for the sum of the weights. The solution to this set of equations will produce a set of weights giving the 'Best Linear Unbiased Estimator' − sometimes referred to as BLUE. This process was named Kriging by Georges Matheron after Danie Krige, who has done a tremendous amount of empirical work on weighted averages. Pronunciation of the word is a controversial topic − I personally prefer 'kridging' (as in bridging). The system of equations is generally referred to as the kriging system, and the estimator produced is the kriging estimator. The variance of the kriging estimator could be found by substitution of the weights into the general estimation variance equation. However, it can be shown that the kriging variance can be written as:
![]()
Earlier in this chapter we took the setup in Fig.5.1, a semi-variogram of the form γ(h)=ph, and allocated a set of weights to each of the three samples. We showed that in that case the estimation variance was 0.0729pl. Now let us see if we can find the 'best' set of weights using the kriging system. Since we have three weights, there are four equations which in the general form are:

and the kriging variance would be:
![]()
The right hand side of the equations are ![]() (S1,A),
(S1,A), ![]() (S2,A) and
(S2,A) and
![]() (S3,A).
(S3,A).
![]() (S1,A)
is the average semi-variogram value between a line of length l and a point on the end of it. This
is the definition of χ(l). So is
(S1,A)
is the average semi-variogram value between a line of length l and a point on the end of it. This
is the definition of χ(l). So is ![]() (S3,A).
(S3,A). ![]() (S2,A) is the average semi-variogram between the
line and a central point. This example was tackled in Chapter 4 and found to be
χ(l/2). Thus we have the right hand side of
the equations and most of the variance. The left hand side of the equations is
made up of the individual sample-with-sample terms. Since all of the samples in
this case are supposed to be points, all of these 'left hand side'
relationships are given by the semi-variogram model. It remains only to
calculate the distances between the pairs and use the model to produce the
terms. The diagonal terms,
(S2,A) is the average semi-variogram between the
line and a central point. This example was tackled in Chapter 4 and found to be
χ(l/2). Thus we have the right hand side of
the equations and most of the variance. The left hand side of the equations is
made up of the individual sample-with-sample terms. Since all of the samples in
this case are supposed to be points, all of these 'left hand side'
relationships are given by the semi-variogram model. It remains only to
calculate the distances between the pairs and use the model to produce the
terms. The diagonal terms, ![]() (S1,S1),
(S1,S1),
![]() (S2,S2)
and
(S2,S2)
and ![]() (S3,S3)
are all zero, since γ(0) = 0 by definition,
(S3,S3)
are all zero, since γ(0) = 0 by definition,
![]() (S1,S2)
is equal to
(S1,S2)
is equal to ![]() (S2,S1), and is
γ(l/2). So is
(S2,S1), and is
γ(l/2). So is ![]() (S2,S3) and
(S2,S3) and
![]() (S3,S2).
(S3,S2).
![]() (S1,S3) is
γ(l) as is
(S1,S3) is
γ(l) as is ![]() (S3,S1). Finally,
(S3,S1). Finally,
![]() (A,A) is F(l) by definition. Putting these
together gives:
(A,A) is F(l) by definition. Putting these
together gives:
|
|
w2 γ(l/2) |
+ w2 γ(l) |
+ λ |
= |
χ(l) |
| w1 γ(l/2) |
|
+ w2 γ(l/2) |
+ λ |
= |
χ(l/2) |
| w1 γ(l) |
+ w2 γ(l/2) |
|
+ λ |
= |
χ(l) |
| w1 |
+ w2 |
+ w3 |
|
= |
1 |
and the kriging variance is
![]()
Up until this point the system does not depend on the actual model for the semi-variogram. Our model was γ(h) = ph and for this example we will take p=4. For the linear semi-variogram, χ(l) = pl/2, so in this case χ(l) = 2l. Similarly, F(l) =4l/3.
Substituting in the above system:
|
|
2lw2 |
+ 4lw2 |
+ λ |
= |
2l |
(1) |
| 2lw1 |
|
+ 2lw2 |
+ λ |
= |
l |
(2) |
| 4lw1 |
+ 2lw2 |
|
+ λ |
= |
2l |
(3) |
| w1 |
+ w2 |
+ w3 |
|
= |
1 |
(4) |
and
![]()
Adding equations (1) and (3) gives
![]()
whilst equation (4) gives
![]()
These two together show that in this case λ=0. Thus we can eliminate λ from the first three equations, and divide all of them through by l. This suggests that the results − the final values of the weights − do not rely on the length being estimated. We have then:
|
|
2w2 |
+ 4w2 |
= |
2 |
(5) |
| 2w1 |
|
+ 2w2 |
= |
1 |
(6) |
| 4w1 |
+ 2w2 |
|
= |
2 |
(7) |
Subtracting equation (5) from equation (7) gives:
![]()
so that equation (6) gives:
![]()
Therefore, w3 = 1/4 and w2 = 1/2. The 'optimal' set of weights for the problem in Fig. 5.1 is therefore (1/4, 1/2, 1/4) and this estimator gives a kriging variance of:
![]()
The final result is therefore that:
the BLUE has weights of (1/4, 1/2, 1/4) and a kriging variance of l/6.
In our previous studies of this particular setup, we found that the arithmetic mean gave an extension variance of pl/18 and that the set of weights (1/8, 3/4, 1/8) gave 7pl/96. To match the example above we should set p=4, so that the variances become 2 l/9 and 7l/24 respectively. The kriging procedure has improved over the arithmetic mean by about 25%, this being the difference in magnitude between the extension variance and the kriging variance. The spurious set of weights which we tried earlier in this chapter give a variance almost twice that of the optimal estimator. Note that in this case, since we have used a linear semi-variogram model, the set of weights is independent of the length being estimated, but the variance is directly proportional to it. For an exercise, see if you can show that the set of weights is also independent of the slope of the semi-variogram, p. Show also that the kriging variance is directly proportional to p, which seems only sensible.
TWO-DIMENSIONAL EXAMPLE
Now let
us return to the familiar uranium example shown in Fig. 5.2. The data −
position co-ordinates and grade values − were given in Table 4.1. We have
five samples, so there will be six equations in the kriging system. The
![]() (Si,Sj) terms on the left hand side of the
equations are all 'point-with-point' relationships, and can be evaluated
directly from the semi-variogram model. The model was spherical, with a range
of influence of 100ft, a sill of 700 (p.p.m.)2 and a nugget effect of 100
(p.p.m.)2. The
(Si,Sj) terms on the left hand side of the
equations are all 'point-with-point' relationships, and can be evaluated
directly from the semi-variogram model. The model was spherical, with a range
of influence of 100ft, a sill of 700 (p.p.m.)2 and a nugget effect of 100
(p.p.m.)2. The ![]() (Si,A) terms are all 'point-with-panel'
relationships and hence are simple combinations of the
H(l,b) auxiliary function. The
(Si,A) terms are all 'point-with-panel'
relationships and hence are simple combinations of the
H(l,b) auxiliary function. The ![]() (A,A) term is, of course, F(l,b).
(A,A) term is, of course, F(l,b).
The kriging system turns out to be:

and the kriging variance would be:
![]()
Solving this system of equations (by computer) gives:

This kriging standard deviation compares favourably with the standard error of the 'inverse distance' weights. The main difference in the weighting is perhaps a surprising one at first sight. Sample 2 is allocated an almost zero weight. In fact, it receives only 20% of the weight on sample 5, which is considerably farther from the block centre. This is because the kriging system automatically takes account of the relationship amongst the samples. Sample 2 provides little extra information about the block in the presence of sample 1, and to a lesser extent samples 3 and 4. To illustrate this point further, let us consider the situation in Fig. 5.3, where sample 3 was moved to the south of the block. The kriging system now becomes:

Note that the only difference between this and the previous system is in row 3 and column 3 on the left hand side. The right hand side is unchanged since we have not changed the relationship of each individual sample to the panel. The new weights are:

The weight on the third sample is now less than that of sample 2. The main movement in weight has been towards the 'northern' samples, 1, 2 and 5, although the largest increase is, naturally, in sample 1. The really striking change is in the value of the estimator which has dropped by 17 p.p.m.
As a third example let us consider the same sampling situation as before, but now with the block rotated through 90 degrees, as in Fig. 5.4.

Fig. 5.4. Block to be estimated is rotated through 90�.
The kriging system for this setup has the same left hand side as the first situation in Fig. 5.2. However, all of the terms on the right hand side have changed, to:
![]()
The weights allocated to the samples change drastically:

The estimator T* takes the value 371.9 p.p.m., and has a standard error of 10.7 p.p.m. Sample 2 has been completely screened out by sample 1, and the influence of sample 5 has also declined somewhat. The biggest surprise, perhaps, is that sample 1 no longer has anything like the importance it had in the previous two examples. There is no method other than kriging in which this shift in 'information value' can be quantified and utilised.
1. We can evaluate the accuracy of any linear estimator if we have a model for the semi-variogram.
2. We can produce the minimum variance unbiased linear estimator using the kriging technique, if we have a model for the semi-variogram.
The standard litany of the advantages of kriging can be found in numerous publications. The points of major importance are:
a) Given the basic assumptions, no trend, and a model for the semi-variogram, kriging always produces the Best Linear Unbiased Estimator.
b) If the proper models are used for the semi-variogram, and the system is set up correctly, there is always a unique solution to the kriging system.
c) If you try to 'estimate' the value at a location which has been sampled, the kriging system will return the sample value as the estimator, and a kriging variance of zero. In other words, you already know that value. This is usually referred to as an 'exact interpolator'.
d) If you have regular sampling, and hence the same sampling/block setup at many different positions within the deposit, it is not necessary to recalculate the kriging system each time.
To round out this chapter, let us return to the simulated iron ore deposit mentioned at the end of Chapter 4. Two sets of samples had been taken. The 50 'random' samples were shown in Fig. 4.14 and the regular grid in Fig. 4.17.
The regular grid actually comprises 41 samples. As before, the 400-metre-square area was divided into 50-metre-square blocks. However, this time the block values were estimated by the method of kriging. The range of influence of the semi-variogram model for this deposit was 100m, so all samples within this distance of a block were included in its estimation. The results are shown in Fig. 5.5, and once again the upper Figure in each block is the estimated value, whilst the lower is the kriging standard deviation, or standard error. For comparison, Fig. 5.6 shows the kriging solution for the case where the area is divided into 100-metre-square blocks. Notice that the kriging standard deviations in all cases are much lower than for the 50-metre blocks.
|
|
|
This once again bears out the principle that it is 'easier' to estimate large areas rather than small ones. Figure 5.7 shows the estimated values for the blocks when using the sample values from the regular grid. The kriging standard deviation for all of these blocks is 2.4%Fe. This is not markedly different from the extension standard deviation of 2.5%Fe. Perhaps our conclusion here must be that with a regular grid of this particular size, the arithmetic mean of the two 'corner' samples is as good an estimator as a weighted average of all samples within 100m of the block. The exterior samples would seem to be superfluous in the circumstances. This conclusion does not hold for the irregular sampling, for which some great improvements in accuracy result from the application of kriging.

Fig.
5.7. Simulated iron ore deposit − block averages kriged from the set of
regular samples − 50 metre blocks.
The usual requirement in ore reserve estimation is the production of block values. However, in many other possible applications of kriging − such as geochemistry or hydrology − the estimation desired is in the form of 'point' values, or a contour map of the variable of interest. Kriging can be used to produce the close grid of values necessary to the plotting of contour maps. In fact, the procedure is very much easier than 'area' estimation, since all the 'average semi-variogram values' reduce to simple values of the semi-variogram model itself. Since all of the observations are made at specified points, the left hand side of the kriging system is 'point-with-point' semi-variogram values. Since the value to be estimated is also at a point, the right hand side is also 'point-with-point' semi-variogram values. Figure 5.8 shows the contour map produced using the 50 randomly chosen samples. The blacked-out area at the top of the map is outside the range of influence of any sample, and hence cannot be estimated.
|
|
|
One of the advantages of kriging as an interpolation technique is that every estimate is accompanied by a corresponding kriging standard deviation. Thus, for any contour map of values, a companion map of 'reliability' can be produced. This is shown in Fig. 5.9. The location of the sample points can easily be seen by the concentration of the low value contours in Fig. 5.9 − the 1%Fe and 2%Fe contours. The highest possible contour value would be 5√2=7.07%Fe, which is the boundary around the blacked out area. This corresponds to trying to estimate the value at a point which is just on the range of influence away from the nearest sample.
The 'unreliable' areas are quite clearly outlined by the 5%Fe contour (the sample standard deviation). A standard error which is larger than the original sample standard deviation denotes a rather unreliable prediction.
|
|
|
Figure 5.10 shows the interpolated contour map using the regular samples, and Fig. 5.11 the corresponding map of the kriged standard deviation. Note that, even though only 41 samples are available, and even though these are on a very large grid (71m), the highest contour value in Fig. 5.11 is only 4%Fe.
An additional advantage of kriging as an estimation technique is that the maps and/or calculations of the 'standard errors' can be produced without actually taking the samples. For example, if infill drilling were proposed on the regular grid, it is fairly obvious from Fig. 5.11 where the new samples should be taken. If a decision was taken to reduce the grid to 50m, i.e. put a hole in the centre of each 4%Fe contour, a complete new map of the resulting standard error could be drawn before setting foot in the field.
. + . + . + .
1. CONSTRUCTION OF SEMI-VARIOGRAMS USING IRREGULAR DATA
All the discussion on the construction of experimental semi-variograms in Chapter 2 was based on samples which were spaced more or less regularly within the deposit. Some grids had missing samples, but this presents no problems. In a situation where the samples are not regularly spaced, approximations must be introduced into the calculation. Suppose we wish to calculate the experimental semi-variogram value for a distance h in a specified direction (say, north-east). The chance of finding any pairs at exactly this separation with irregular sampling is quite small. We therefore place a 'tolerance' on each specification. We look for samples more-or-less distance h apart (within δh) and more-or-less north-east (within ±δθ) − see Fig. 6.1 for illustration. The size of the tolerances depends greatly on the structure of the deposit. This is rather a circular argument, since we do not know the structure until we construct the semi-variogram. If the deposit is anisotropic, the semi-variogram will be more sensitive to the tolerance placed on the search angle. A good practice is to try several δθ values, and a narrow range of δh values. δh should always be small relative to the sample spacing. As a rule of thumb, you could try δθ=5, 0, 0, 5 degrees and δh equal to 10% of the average sample spacing.

Fig. 6.1. Search area defined by tolerances on
angle and distance between pair in experimental semi-variogram.
2. SAMPLING ERRORS
This is a field which is skated over in most geostatistical treatises, and I intend to emulate my predecessors in this. Random errors introduced during sampling will contribute to the nugget effect in the semi-variogram, i.e. they will show as an increase in the 'unpredictable' component of the value. Similarly, core loss will also contribute to the nugget effect. Other possible contributions of 'error' − apart from the mineralisation itself − are analytical errors in valuation, subsampling and so on. However, the contribution of these errors should not be over-emphasised. In my Cornish tin example, we carried out a special sampling scheme to determine the 'size' of the operator error in the vanning assay. This turned out to be 3% of the total nugget effect. The other 97% was due to the random nature of the mineralisation.
Systematic errors, be they sampling, analytical or whatever, will not be picked up by Geostatistics and will be transferred to any estimates produced.
3. TRENDS
We have seen in Chapter 2 how to detect the presence of a significant trend within the deposit. If we construct the experimental semi-variogram assuming no trend, then the neglected component will show in the graph. If it is a periodic trend, it will show as a regular rise and fall in the semi-variogram. If it is a polynomial type of trend, it will show in the addition of a parabolic component to the 'true' semi-variogram. There are cases where a trend may exist but can be safely ignored, as in the silver example in Chapter 2. However, there are others in which this is not the case, e.g. the rainfall example. Kriging, as such, cannot be used in the presence of a strong trend. It will give erroneous and biased results. Some technique such as Universal Kriging, or the newer Generalised Covariances must be applied if the user is determined to use Geostatistics. My experience in the application of Geostatistics in the presence of trend is voluntarily non-existent.
4. ANISOTROPY
This is perhaps the easiest 'problem' to tackle. Most frequently, the form of the anisotropy is different ranges of influence in different directions. For example, a porphyry molybdenum may have a range of influence of 70m vertically through the deposit, and one of 350m in all horizontal directions. This is very simply tackled by changing the units of measurement in one direction so that the ranges appear to be equal. In the example cited, we might change all horizontal measurements to multiples of 5m instead of 1. This gives a horizontal range of 70 units. Then, when estimating block values, it must be remembered that all horizontal distances must be expressed in units of 5m. Diagonal distances must be corrected accordingly. For example, a block defined as 50 by 50 by 20m, will be estimated as if it were 10 units by 10 units by 20 units. Similarly, the distance between samples must be corrected to this new 'co-ordinate' system. The simplest way to tackle this (inside a computer) is to correct all measurements before embarking on the estimation. The final estimates and standard errors will be as they should be, and need no 'uncorrection'.
5. IRREGULAR SHAPED STOPES OR BLOCKS
In the estimation problems discussed, all panels and blocks were rectangular in shape. The auxiliary functions are only relevant to such panels, and so cannot be used with, say, stope panels such as that shown in Fig. 6.2.

Fig. 6.2. Estimation of irregularly shaped stope.
These
shapes can only be tackled using numerical approximations and a computer. The
principle of the approximation is the same as that applied in calculating the
three-dimensional F function in Chapter 3. Instead of considering all
of the infinite number of points within the stope, we use a
finite grid of points to represent it. The number of points is in question, but
general agreement seems to lie in the range 64 to 100. This then means that
values such as ![]() (S,A)
are average semi-variograms between 'the sample and each point on the grid in
the stope'. A computer program will evaluate
the model semi-variogram value between each pair of points and then produce the
average semi-variogram value required. This principle also applies to irregular
shapes in three dimensions.
(S,A)
are average semi-variograms between 'the sample and each point on the grid in
the stope'. A computer program will evaluate
the model semi-variogram value between each pair of points and then produce the
average semi-variogram value required. This principle also applies to irregular
shapes in three dimensions.
6. THREE-DIMENSIONAL KRIGING
This leads us on nicely to one of my hobby horses − the performance of kriging estimation in three dimensions. This problem is most often encountered in the planning of open pits from borehole results. The 'standard' technique is to make an approximation such as described in Section 5 above. A suggested alternative, which uses less computer time, is as follows:
i. slice the deposit into benches;
ii. represent each block as a panel at a level midway up the bench;
iii. approximate this block by a grid of points in two dimensions;
iv. take each borehole intersection with the bench and call this a 'point' midway up the bench;
v. put all the slices back and krige.
The semi-variogram supposedly used in the kriging is that of 'bench composites', i.e. sections of length equal to the height of the bench. This technique is adequate if all boreholes are complete, and if they start and stop at more or less the same level. However, there are other situations which it does not represent adequately. Figure 6.3 illustrates some of these. All of these boreholes would be averaged over the bench, positioned halfway up the bench and allocated a length equal to the height of the bench.

Fig. 6.3. Some problems with the
simplistic approach to three-dimensional kriging procedures
Borehole A has core loss part way down the bench; borehole B is inclined so that the composite may be substantially longer than supposed; borehole C stops before it reaches the bottom of the bench and borehole D does not start until halfway through. All of these situations can be tackled by taking a truly three-dimensional approach to the problem. Computer packages are now available on the market for the above described method, the point approximation method, and the three-dimensional approach advocated in my own papers.
7. BIAS ON THE GRADE/TONNAGE CURVE
After a mine has been estimated on a block-by-block basis, it is usual to construct the so-called 'production' grade/tonnage curve. Unfortunately, even with the best estimates possible (kriging) this grade/tonnage curve will still be biased. There are two contributory factors to this bias. The first factor is that the selection criterion (cutoff value) is being applied to the estimate of the block grade. No matter how accurate that estimate, it will not exactly equal the true value of the block. Thus, if a block is estimated to be just below the cutoff value, there is a finite probability that the true value is above cutoff. However, this block will be sent as waste. On the other hand there will be blocks estimated as being above cutoff which are actually below cutoff. These will be sent as ore. Thus, we will have payable blocks sent to waste and unpayable ore sent to the mill. This will result in production figures which will differ from those predicted by the supposed grade/tonnage curve calculated on the block estimates. The major difference will be a lowering in the grade of ore milled.
The second bias in the grade/tonnage curve is one introduced by the volume-variance relationship. The estimates of the block values will not necessarily have the same variance as the actual block values. You may remember we discussed this matter in connection with the Cornish tin example in Chapter 3. There the estimator was the average grade of two 125-ft strips of ground, whilst the panel was 125 by 100ft. The variance of these two quantities will not be the same. In most situations − except for point kriging − the variance of the estimator will be larger than that of the actual blocks. Thus the grade/tonnage curve based on the block estimates will be biased towards lower tonnage and an over-optimistic average grade. This problem is currently being investigated by the staff at Fountainebleau under the title 'Disjunctive Kriging'. A simple, empirically justified technique to correct this bias is currently under investigation at the Royal School of Mines.
SUMMARY
This summary is more for the book as a whole than for this chapter particularly. I have endeavoured to give a perhaps over-simplistic presentation of the theory and practice of the estimation technique known as kriging. Readers who find this approach tedious are referred to the definitive (and more mathematical) works mentioned in the bibliography. I have also endeavoured to detail the practical difficulties which arise in applying the technique and to suggest some ways of overcoming them.
. + . + . + .
The purpose of this bibliography is to detail some papers and books which might assist the 'new' reader to pursue the theory and applications of geostatistics. The references have been split by sub-headings to give a clearer notion of what the reader should hope to get from them.
1. Good introductory papers
These are fairly rare, and confined to the efforts of a few authors.
P. I. Brooker has published a few, such as:
'Robustness of geostatistical calculations: a case study', 1977. Proc. Australasian Institution of Mining and Metallurgy, vol. 264, pp. 61-8.
A. G. Royle is another good author, mostly publishing in the Transactions of the Institution of Mining and Metallurgy. One of his most recent papers is:
'Global estimates of ore reserves', 1977, vol. 86, pp. A9-17.
A. J. Sinclair has turned out two or three widely available papers, all concerned with explaining the application of geostatistics to particular deposits. Two such are:
'A geostatistical study of the Eagle copper vein, Northern British Columbia', Canadian Inst. Min. Metall., 1974, vol. 67, no. 746, pp. 131-42.
'Geostatistical investigation of the Kutcho Creek deposit, Northern British Columbia', Mathematical Geology, 1978, vol. 10, no. 3, pp. 273-88.
2. Definitive volumes
Matheron, G. The Theory of Regionalised Variables and its Applications, 1971, Cahier No. 5, Centre de Morphologie Mathématique de Fontainebleau, 211 pp.
David, M. Geostatistical Ore Reserve Estimation, 1977, Elsevier, 364pp.
Guarascio, M., David, M. and Huijbregts, C. (Eds) Advanced Geostatistics in the Mining Industry, 1976, D. Reidel, Dordrecht, Holland, 491 pp.
Journel, A.G. and Huijbregts, C. Mining Geostatistics, 1978, Academic Press, 600pp.
3. Other introductory texts
Rendu, J-M. An Introduction to Geostatistical Methods of Mineral Evaluation, Monograph of the South African Inst. Min. Metall, 1978, 100 pp.
Royle, A. G. A Practical Introduction to Geostatistics. Course Notes of the University of Leeds, Dept. of Mining and Mineral Sciences, Leeds, 1971.
4. Other applications
Clark, M. W.and Thornes, J. B. Forwards Estimation from Incomplete Data by the Theory of Regionalised Variables, Non-Sequential Water Quality Records Project: Working Paper No. 4, 1975, LSE, 9pp.
Delhomme, J. P. and Delfiner, P. Application du krigeage a l'optimisation d'une compagne pluviometrique en zone aride, Symposium on the Design of Water Resources Projects with Inadequate Data, 1973, UNESCO-WHO-IAHS, Madrid, Spain, pp. 191-210.
Huijbregts, C. Courbes d'isovariance en cartographie automatique Colloque sur la Visualisation, 1971, Nancy (Ecole National Superieure de Geologie), 11 pp.
Olea, R. A. 'Optimal contour mapping using universal kriging', J. Geophys Res, 1974, vol. 79, No. 5, pp. 696-702.
Poissonet, M., Millier, C. and Serra, J. Morphologie mathematique et silviculture, 1970, 3ieme Conference du groupe des Staticiens Forestiers, Paris. pp. 287-307.
5. Historical perspective
de Wijs, H. J. 'Method of successive differences applied to mine sampling', Trans. Inst. Min. Metall., 1972, vol. 81, No. 788, pp. A129-32.
Journel, A. G. 'Geostatistics and sequential exploration', Mining Engineering, 1973, vol. 25, No. 10, pp.44-8.
Krige, D. G. 'A statistical approach to some basic mine valuation problems on the Witwatersrand', J. Chem. Metall and Min. Soc. South Africa, 1951, vol. 52, No. 6, pp. 119-39.
Matheron, G. 'Principles of geostatistics', Economic Geology, 1963, vol. 58, pp. 1246-66.
Sichel, H. S. The estimation of means and associated confidence limits for small samples from lognormal populations, Symposium on mathematical statistics computer applications in ore valuation, S. Afr. Inst. Min. Metall, 1966, pp. 106-23.
6. Author's papers
These papers have been published to assist workers who wish to apply geostatistics to their own problems, and who wish to use a computer and/or numerical approximations.
'Some auxiliary functions for the spherical model of geostatistics', Computers and Geosciences, 1976, Vol. 1, No. 4, pp. 255-63.
'Some practical computational aspects of mine planning', in Advanced Geostatistics in the Mining Industry, ed. M. Guarascio et al., 1976, pp. 391-9, D. Reidel, Dordrecht, Holland.
'Practical kriging in three dimensions', Computers and Geosciences, 1977, Vol. 3, No. 1, pp. 173-80.
'Regularisation of a semi-variogram', >Computers and Geosciences, 1977, Vol. 3, No. 2, pp. 341-6.
7. Some useful journals to watch or read
The following Journals often contain papers on Geostatistics and related topics. Added to this list should be the Transactions or Proceedings of the numerous 'Institutions of Mining and Metallurgy', such as those of the UK, Canada, South Africa and Australasia.
Mathematical Geology
Computers and Geosciences
Economic Geology
Water Resources Research
Engineering and Mining Journal
Publications of the Kansas Geological Survey, especially the series on Spatial Analysis.
Proceedings of the annual Applications of Computers in the Minerals Industry (APCOM), various venues.
Canadian Inst. Min. Metall. Special Volumes.
. + . + . + .
Table 2.1. Calculation of experimental semi-variogram values in two major directions for iron ore example on square grid
| Distance between | Experimental | Number of | |
| Direction | samples (ft) | semi-variogram | pairs |
| East-west | 100 | 1.46 | 36 |
| 200 | 3.30 | 33 | |
| 300 | 4.31 | 27 | |
| 400 | 6.70 | 23 | |
| North-south | 100 | 5.35 | 36 |
| 200 | 9.87 | 27 | |
| 300 | 18.88 | 21 |
Table 2.2.
Calculation of semi-variogram in diagonal direction for iron ore
| Distance between | Experimental | Number of | |
| Direction | samples (ft) | semi-variogram | pairs |
| North-west | 141 | 7.06 | 32 |
| South-east | 282 | 12.95 | 21 |
| diagonal | 424 | 30.85 | 13 |
Table 2.3.
Hypothetical borehole log from lead/zinc deposit − Zinc values
|
|
|
|
Table 2.4. Calculated
experimental semi-variogram from Lead/Zinc deposit
|
|
Table 2.5. Experimental semi-variogram from 400m adit --- silver values
| Distance between | Experimental | Distance between | Experimental | Distance between | Experimental | Distance between | Experimental | |||
| samples(m) | semi-variogram | samples(m) | semi-variogram | samples(m) | semi-variogram | samples (m) | semi-variogram | |||
| 1 | 0.42 | 26 | 8.94 | 51 | 10.22 | 76 | 12.26 | |||
| 2 | 0.72 | 27 | 8.48 | 52 | 9.96 | 77 | 11.69 | |||
| 3 | 0.92 | 28 | 7.65 | 53 | 11.64 | 78 | 12.30 | |||
| 4 | 1.36 | 29 | 7.04 | 54 | 11.93 | 79 | 11.63 | |||
| 5 | 1.69 | 30 | 6.49 | 55 | 12.62 | 80 | 12.98 | |||
| 6 | 2.03 | 31 | 7.26 | 56 | 11.35 | 81 | 15.78 | |||
| 7 | 1.95 | 32 | 7.47 | 57 | 10.18 | 82 | 17.42 | |||
| 8 | 2.75 | 33 | 7.66 | 58 | 10.69 | 83 | 16.72 | |||
| 9 | 3.65 | 34 | 9.54 | 59 | 10.03 | 84 | 17.20 | |||
| 10 | 4.05 | 35 | 10.98 | 60 | 9.81 | 85 | 17.16 | |||
| 11 | 3.44 | 36 | 10.82 | 61 | 10.23 | 86 | 14.67 | |||
| 12 | 3.55 | 37 | 10.58 | 62 | 11.85 | 87 | 14.12 | |||
| 13 | 3.24 | 38 | 10.21 | 63 | 11.27 | 88 | 14.56 | |||
| 14 | 3.07 | 39 | 10.08 | 64 | 13.01 | 89 | 16.04 | |||
| 15 | 4.52 | 40 | 8.28 | 65 | 13.61 | 90 | 17.81 | |||
| 16 | 5.23 | 41 | 8.08 | 66 | 14.17 | 91 | 20.96 | |||
| 17 | 6.53 | 42 | 9.34 | 67 | 11.75 | 92 | 22.70 | |||
| 18 | 6.41 | 43 | 9.55 | 68 | 9.91 | 93 | 23.20 | |||
| 19 | 5.98 | 44 | 9.87 | 69 | 10.12 | 94 | 24.37 | |||
| 20 | 5.72 | 45 | 10.45 | 70 | 9.56 | 95 | 23.67 | |||
| 21 | 5.26 | 46 | 10.23 | 71 | 10.91 | 96 | 21.66 | |||
| 22 | 6.46 | 47 | 8.87 | 72 | 11.98 | 97 | 21.44 | |||
| 23 | 7.01 | 48 | 9.19 | 73 | 12.13 | 98 | 22.94 | |||
| 24 | 7.55 | 49 | 10.19 | 74 | 11.45 | 99 | 22.29 | |||
| 25 | 8.06 | 50 | 10.73 | 75 | 12.14 | 100 | 22.16 |
Table 2.6. Spherical semi-variogram model for silver values up to h = 75m
| Distance between | Theoretical |
| samples (m) | semi-variogram |
| 0 | 0.00 |
| 5 | 1.64 |
| 10 | 3.26 |
| 15 | 4.80 |
| 20 | 6.25 |
| 25 | 7.56 |
| 30 | 8.71 |
| 35 | 9.66 |
| 40 | 10.38 |
| 45 | 10.84 |
| 50 | 11.00 |
| >50 | 11.00 |
Table 2.7 Attempts to fit exponential models to silver semi-variogram
| Distance between | Theoretical semi-variograms | |||
| samples (m) | a=33,C=14 | a=50,C=14 | a=50,C=15 | a=50,C=16 |
| 5 | 1.97 | 1.33 | 1.43 | 1.52 |
| 10 | 3.66 | 2.54 | 2.72 | 2.90 |
| 15 | 5.11 | 3.63 | 3.89 | 4.15 |
| 20 | 6.36 | 4.62 | 4.95 | 5.27 |
| 25 | 7.44 | 5.51 | 5.90 | 6.30 |
| 30 | 8.36 | 6.32 | 6.77 | 7.22 |
| 35 | 9.15 | 7.05 | 7.55 | 8.05 |
| 40 | 9.83 | 7.71 | 8.26 | 8.81 |
| 45 | 10.42 | 8.31 | 8.90 | 9.49 |
| 50 | 10.92 | 8.85 | 9.48 | 10.11 |
| 55 | 11.36 | 9.34 | 10.01 | 10.67 |
| 60 | 11.73 | 9.78 | 10.48 | 11.18 |
| 65 | 12.05 | 10.18 | 10.91 | 11.64 |
| 70 | 12.32 | 10.55 | 11.30 | 12.05 |
Table 2.8 Experimental semi-variogram from a
disseminated nickel deposit (logarithm of grade)
|
|
|
Table 2.9 First
attempt to fit a mixture of Spherical models to the experimental nickel semi-variogram (parameters in text)
| Distance | Theoretical | Distance | Theoretical | |
| between samples (m) | semi-variogram | between samples (m) | semi-variogram | |
| 0 | 0.00 | 25 | 2.36 | |
| 2 | 0.77 | 30 | 2.42 | |
| 4 | 1.12 | 35 | 2.48 | |
| 6 | 1.44 | 40 | 2.52 | |
| 8 | 1.73 | 45 | 2.54 | |
| 10 | 1.96 | 50 | 2.55 | |
| 12 | 2.12 | 55 | 2.55 | |
| 14 | 2.20 | 60 | 2.55 | |
| 16 | 2.23 | |||
| 18 | 2.26 | |||
| 20 | 2.29 |
Table 2.10 Final attempt to fit a mixture of Spherical models to the experimental Nickel semi-variogram (parameters in text)
| Distance between | Theoretical | Distance between | Theoretical | |
| samples (m) | semi-variogram | samples (m) | semi-variogram | |
| 0 | 0.00 | 20 | 2.03 | |
| 2 | 0.74 | 25 | 2.14 | |
| 4 | 1.05 | 30 | 2.24 | |
| 6 | 1.34 | 35 | 2.33 | |
| 8 | 1.58 | 40 | 2.40 | |
| 10 | 1.75 | 45 | 2.46 | |
| 12 | 1.85 | 50 | 2.51 | |
| 14 | 1.89 | 55 | 2.54 | |
| 16 | 1.94 | 60 | 2.55 | |
| 18 | 1.99 |
Table 3.6
Comparison of grade/tonnage calculations for point and block values for combined metal (Lead/Zinc) deposit
|
POINTS |
BLOCKS |
||
|
proportion |
average grade |
proportion |
average grade |
Cutoff |
above cutoff |
|
above cutoff |
|
4 |
0.934 |
12.62 |
0.988 |
12.10 |
6 |
0.800 |
13.90 |
0.912 |
12.68 |
8 |
0.643 |
15.58 |
0.758 |
13.82 |
10 |
0.499 |
17.48 |
0.576 |
15.34 |
Table 3.7. Comparison of grade/tonnage
calculations for point and block values for uranium deposit
|
POINTS |
BLOCKS |
||
|
proportion |
average grade |
proportion |
average grade |
Cutoff |
above cutoff |
|
above cutoff |
|
0.05 |
0.622 |
0.47 |
0.712 |
0.41 |
0.10 |
0.452 |
0.62 |
0.527 |
0.53 |
0.15 |
0.355 |
0.75 |
0.414 |
0.64 |
0.20 |
0.291 |
0.88 |
0.337 |
0.75 |
Table 4.1 Positions
and values on hypothetical Uranium estimation problem
| Easting | Northing | Grade | |
| Point | (ft) | (ft) | U3O8 |
| A | 4150 | 2340 | |
| 1 | 4170 | 2332 | 400 |
| 2 | 4200 | 2340 | 380 |
| 3 | 4160 | 2370 | 450 |
| 4 | 4150 | 2310 | 280 |
| 5 | 4080 | 2340 | 320 |
Table 4.2 Auxiliary function χ(L,B) for Spherical model with range 1.0 and sill 1.0
| B | ||||||||||
| L | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | 1.0 |
| .10 | .098 | .136 | .178 | .222 | .266 | .309 | .350 | .390 | .428 | .464 |
| .20 | .164 | .194 | .229 | .268 | .307 | .346 | .385 | .422 | .458 | .491 |
| .30 | .233 | .257 | .288 | .321 | .356 | .392 | .427 | .462 | .495 | .526 |
| .40 | .302 | .322 | .348 | .378 | .409 | .441 | .474 | .505 | .535 | .564 |
| .50 | .368 | .385 | .408 | .434 | .462 | .492 | .521 | .550 | .577 | .603 |
| .60 | .430 | .445 | .466 | .489 | .515 | .541 | .568 | .594 | .619 | .642 |
| .70 | .488 | .502 | .520 | .541 | .564 | .588 | .612 | .636 | .658 | .680 |
| .80 | .542 | .554 | .570 | .589 | .610 | .631 | .653 | .674 | .695 | .714 |
| .90 | .589 | .600 | .614 | .632 | .650 | .670 | .689 | .708 | .727 | .744 |
| 1.00 | .629 | .639 | .653 | .668 | .685 | .703 | .720 | .737 | .754 | .769 |
| 1.20 | .691 | .699 | .711 | .723 | .737 | .752 | .767 | .781 | .795 | .808 |
| 1.40 | .735 | .742 | .752 | .763 | .775 | .788 | .800 | .812 | .824 | .835 |
| 1.60 | .768 | .775 | .783 | .793 | .803 | .814 | .825 | .836 | .846 | .856 |
| 1.80 | .794 | .800 | .807 | .816 | .825 | .835 | .845 | .854 | .863 | .872 |
| 2.00 | .815 | .820 | .826 | .834 | .842 | .851 | .860 | .869 | .877 | .885 |
| 2.50 | .852 | .856 | .861 | .867 | .874 | .881 | .888 | .895 | .902 | .908 |
| 3.00 | .876 | .880 | .884 | .889 | .895 | .901 | .907 | .912 | .918 | .923 |
| 3.50 | .894 | .897 | .901 | .905 | .910 | .915 | .920 | .925 | .930 | .934 |
| 4.00 | .907 | .910 | .913 | .917 | .921 | .926 | .930 | .934 | .938 | .942 |
| 5.00 | .926 | .928 | .931 | .934 | .937 | .941 | .944 | .947 | .951 | .954 |
| B | ||||||||||
| L | 1.2 | 1.4 | 1.6 | 1.8 | 2.0 | 2.5 | 3.0 | 3.5 | 4.0 | 5.0 |
| .10 | .526 | .577 | .619 | .653 | .683 | .738 | .777 | .807 | .829 | .861 |
| .20 | .550 | .598 | .638 | .671 | .698 | .751 | .788 | .816 | .837 | .868 |
| .30 | .580 | .625 | .662 | .693 | .719 | .768 | .803 | .828 | .848 | .877 |
| .40 | .614 | .655 | .689 | .718 | .741 | .787 | .819 | .842 | .861 | .887 |
| .50 | .649 | .687 | .718 | .743 | .765 | .806 | .835 | .857 | .873 | .897 |
| .60 | .684 | .718 | .746 | .769 | .788 | .825 | .852 | .871 | .886 | .907 |
| .70 | .717 | .747 | .772 | .793 | .811 | .844 | .867 | .885 | .898 | .917 |
| .80 | .747 | .774 | .797 | .815 | .831 | .861 | .881 | .897 | .909 | .926 |
| .90 | .774 | .798 | .818 | .835 | .849 | .875 | .894 | .908 | .919 | .934 |
| 1.00 | .796 | .818 | .836 | .851 | .864 | .888 | .905 | .917 | .927 | .941 |
| 1.20 | .830 | .848 | .864 | .876 | .886 | .906 | .920 | .931 | .939 | .950 |
| 1.40 | .854 | .870 | .883 | .894 | .903 | .920 | .932 | .941 | .948 | .958 |
| 1.60 | .873 | .886 | .898 | .907 | .915 | .930 | .940 | .948 | .954 | .963 |
| 1.80 | .887 | .899 | .909 | .917 | .924 | .938 | .947 | .954 | .959 | .967 |
| 2.00 | .898 | .909 | .918 | .926 | .932 | .944 | .952 | .959 | .963 | .970 |
| 2.50 | .918 | .927 | .934 | .940 | .946 | .955 | .962 | .967 | .971 | .976 |
| 3.00 | .932 | .939 | .945 | .950 | .955 | .963 | .968 | .972 | .976 | .980 |
| 3.50 | .942 | .948 | .953 | .957 | .961 | .968 | .973 | .976 | .979 | .983 |
| 4.00 | .949 | .955 | .959 | .963 | .966 | .972 | .976 | .979 | .982 | .985 |
| 5.00 | .959 | .964 | .967 | .970 | .973 | .978 | .981 | .983 | .985 | .988 |
Table 4.3. Auxiliary function H(L,B) for
Spherical model with range 1.0 and sill 1.0
| B | ||||||||||
| L | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .10 |
| .10 | .114 | .177 | .243 | .310 | .374 | .436 | .494 | .546 | .593 | .633 |
| .20 | .177 | .227 | .285 | .346 | .406 | .464 | .518 | .568 | .613 | .651 |
| .30 | .243 | .285 | .336 | .390 | .445 | .499 | .550 | .597 | .639 | .674 |
| .40 | .310 | .346 | .390 | .439 | .489 | .539 | .586 | .629 | .668 | .701 |
| .50 | .374 | .406 | .445 | .489 | .535 | .580 | .623 | .663 | .698 | .728 |
| .60 | .436 | .464 | .499 | .539 | .580 | .621 | .660 | .697 | .728 | .755 |
| .70 | .494 | .518 | .550 | .586 | .623 | .660 | .696 | .729 | .757 | .781 |
| .80 | .546 | .568 | .597 | .629 | .663 | .697 | .729 | .758 | .783 | .805 |
| .90 | .593 | .613 | .639 | .668 | .698 | .728 | .757 | .783 | .806 | .826 |
| 1.00 | .633 | .651 | .674 | .701 | .728 | .755 | .781 | .805 | .826 | .843 |
| 1.20 | .694 | .709 | .729 | .751 | .774 | .796 | .818 | .837 | .855 | .869 |
| 1.40 | .738 | .751 | .767 | .786 | .806 | .825 | .844 | .861 | .875 | .888 |
| 1.60 | .771 | .782 | .797 | .813 | .830 | .847 | .863 | .878 | .891 | .902 |
| 1.80 | .796 | .806 | .819 | .834 | .849 | .864 | .879 | .892 | .903 | .913 |
| 2.00 | .817 | .826 | .837 | .850 | .864 | .878 | .891 | .902 | .913 | .921 |
| 2.50 | .853 | .860 | .870 | .880 | .891 | .902 | .913 | .922 | .930 | .937 |
| 3.00 | .878 | .884 | .891 | .900 | .909 | .918 | .927 | .935 | .942 | .948 |
| 3.50 | .895 | .900 | .907 | .914 | .922 | .930 | .938 | .944 | .950 | .955 |
| 4.00 | .908 | .913 | .919 | .925 | .932 | .939 | .945 | .951 | .956 | .961 |
| 5.00 | .927 | .930 | .935 | .940 | .946 | .951 | .956 | .961 | .965 | .969 |
| B | ||||||||||
| L | 1.2 | 1.4 | 1.6 | 1.8 | 2.0 | 2.5 | 3.0 | 3.5 | 4.0 | 5.0 |
| .10 | .694 | .738 | .771 | .796 | .817 | .853 | .878 | .895 | .908 | .927 |
| .20 | .709 | .751 | .782 | .806 | .826 | .860 | .884 | .900 | .913 | .930 |
| .30 | .729 | .767 | .797 | .819 | .837 | .870 | .891 | .907 | .919 | .935 |
| .40 | .751 | .786 | .813 | .834 | .850 | .880 | .900 | .914 | .925 | .940 |
| .50 | .774 | .806 | .830 | .849 | .864 | .891 | .909 | .922 | .932 | .946 |
| .60 | .796 | .825 | .847 | .864 | .878 | .902 | .918 | .930 | .939 | .951 |
| .70 | .818 | .844 | .863 | .879 | .891 | .913 | .927 | .938 | .945 | .956 |
| .80 | .837 | .861 | .878 | .892 | .902 | .922 | .935 | .944 | .951 | .961 |
| .90 | .855 | .875 | .891 | .903 | .913 | .930 | .942 | .950 | .956 | .965 |
| 1.00 | .869 | .888 | .902 | .913 | .921 | .937 | .948 | .955 | .961 | .969 |
| 1.20 | .891 | .907 | .918 | .927 | .935 | .948 | .956 | .963 | .967 | .974 |
| 1.40 | .907 | .920 | .930 | .938 | .944 | .955 | .963 | .968 | .972 | .978 |
| 1.60 | .918 | .930 | .939 | .945 | .951 | .961 | .967 | .972 | .975 | .980 |
| 1.80 | .927 | .938 | .945 | .952 | .956 | .965 | .971 | .975 | .978 | .983 |
| 2.00 | .935 | .944 | .951 | .956 | .961 | .969 | .974 | .978 | .980 | .984 |
| 2.50 | .948 | .955 | .961 | .965 | .969 | .975 | .979 | .982 | .984 | .987 |
| 3.00 | .956 | .963 | .967 | .971 | .974 | .979 | .983 | .985 | .987 | .990 |
| 3.50 | .963 | .968 | .972 | .975 | .978 | .982 | .985 | .987 | .989 | .991 |
| 4.00 | .967 | .972 | .975 | .978 | .980 | .984 | .987 | .989 | .990 | .992 |
| 5.00 | .974 | .978 | .980 | .983 | .984 | .987 | .990 | .991 | .992 | .994 |
Table 4.4. Auxiliary function
γ(L,B) for Spherical model with range 1.0 and sill 1.0
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table 4.4. Auxiliary function γ(L,B) for Spherical
model with range 1.0 and sill 1.0
Table 4.5 Random samples taken from a simulated iron ore example
. + . + . + . Link to the 'new' book, courses, software and much more Link to the author's personal web page . + . + . + .
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||









